文章摘要
【关 键 词】 长文本处理、稀疏注意力、算力优化、模型性能、上下文窗口
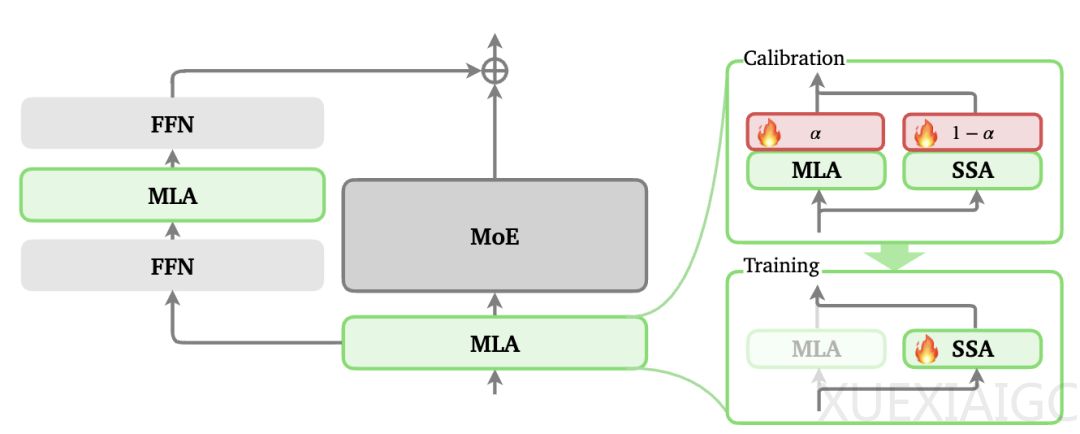
美团龙猫LongCat系列发布全新稀疏注意力机制LoZA(LongCat ZigZag Attention),重点解决长文本任务的理解和算力难题。该技术通过改造原有的全注意力MLA机制,将模型长文本处理能力从256K扩展到1M上下文窗口,同时显著提升解码速度。相比于之前的MLA机制,LoZA仅修改了50%的核心模块,却在性能与效率上实现了双重突破。
LoZA的核心创新在于采用两步优化策略。首先,通过引入可学习权重α对MLA模块进行全局筛查,α值高低直接反映模块对模型性能的影响程度。低α值模块被判定为可替代性强,随后被替换为计算复杂度仅为O(L·S)的流式稀疏注意力SSA,形成独特的ZigZag交错结构。这种设计将整体计算复杂度从平方级降至线性级,在保持模型理解能力的同时,显著降低算力消耗。
技术细节方面,LoZA设置了1024Token的稀疏窗口机制,每个窗口包含1个全局块和7个局部块,分别负责整体关联和局部细节捕捉。这种混合设计确保模型在关注局部信息时不丢失全局上下文。值得注意的是,该改造无需从头训练,可在中期训练阶段低成本实现。
实测数据显示,LoZA在速度与性能上均有突出表现。处理128K上下文时解码速度提升10倍,256K上下文预加载速度提高50%,同时节省30%的生成算力。性能测试中,LoZA不仅在日常任务中与原版模型持平,在MRCR长文本测试中甚至超越Qwen-3模型,展现出更好的稳定性和处理能力。
未来,团队计划进一步开发动态稀疏比例功能,使模型能根据文本长度自动调整注意力机制配置,并探索在多模态长内容处理中的应用潜力。这项技术突破为大规模语言模型的高效部署提供了新思路,特别是在需要处理超长文本的实际应用场景中具有重要价值。
原文和模型
【原文链接】 阅读原文 [ 998字 | 4分钟 ]
【原文作者】 量子位
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★☆☆☆


相关文章


