美团LongCat-Next:把图像、声音、文字都变成Token,然后呢?
文章摘要
【关 键 词】 多模态突破、离散原生、视觉生成、音频统一、语义交融
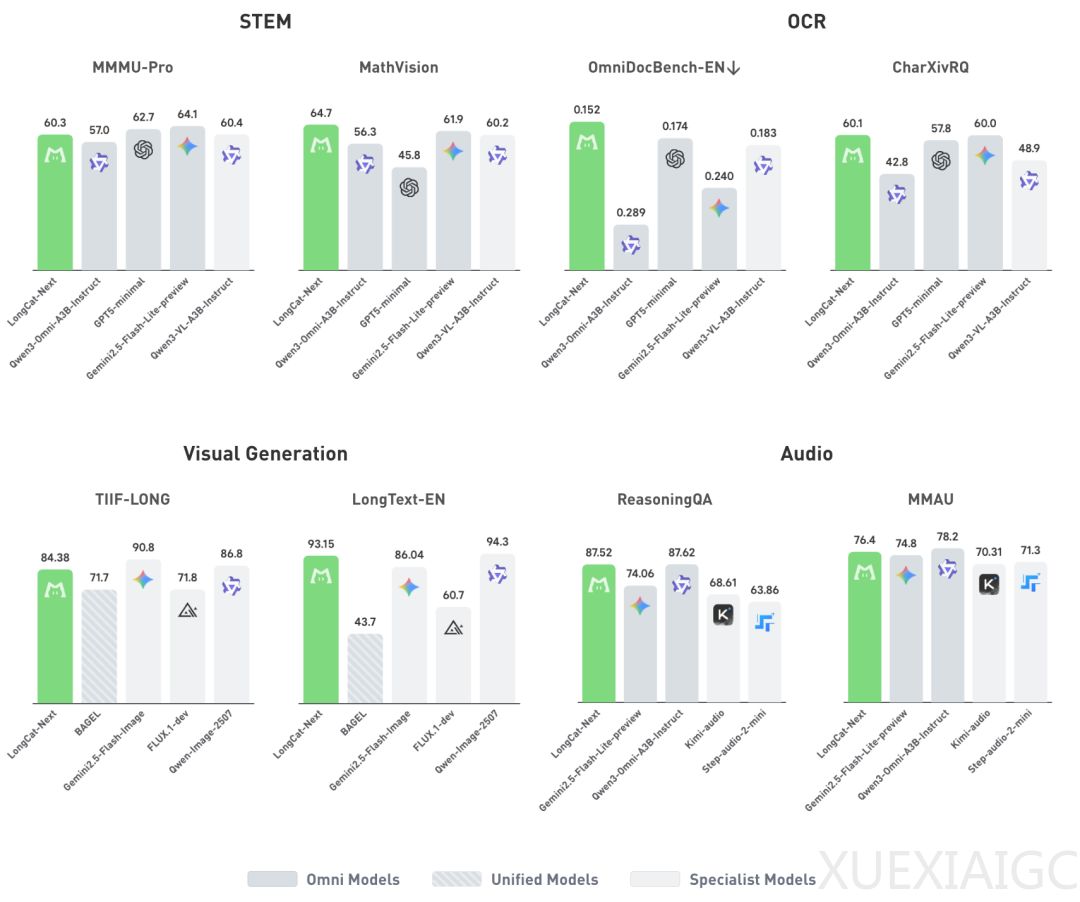
LongCat-Next 是美团发布的一项多模态大模型里程碑式成果,其核心在于首次在纯离散框架下实现了与专用连续模型相当的细粒度视觉理解能力。该模型基于 LongCat-Flash-Lite MoE 架构构建,总参数量 68.5B,但激活参数仅为 3B,能统一处理文本、图像与音频三种模态。它直接挑战了“将视觉信息离散化必然导致细节丢失”的传统认知,并在 OCR、复杂图表等任务上展现出强竞争力,尤其在与同等规模专用视觉模型 Qwen3-VL-A3B 的对比中不落下风。
在图像生成方面,LongCat-Next 展现出突出的长文本理解与文字渲染能力,整体生成质量可比肩专用文生图模型 Flux-dev;在音频处理上,语音识别与理解表现优于 Gemini 3.1 Flash-Lite preview 及 MiMo-Audio 等同级别模型。其特别之处在于打破了“视觉理解与生成存在优化冲突”的惯常认知——实验证明,在相同 token 预算下,联合训练理解与生成不仅未产生互斥,反而是理解信号对生成质量起到正向促进作用。这种协同效果源于跨模态的语义融合现象:当所有模态以离散 token 形式共享嵌入空间共同训练后,视觉 token 与文本 token 在表示空间中形成自然交织分布。
为保障离散化过程中的语义完整性,LongCat-Next 引入 dNaViT(Discrete Native Resolution Vision Transformer)视觉 Tokenizer,通过 SAE(语义对齐编码器)、RVQ 压缩及原生分辨率处理三层机制,在降低信息损失的同时保留高维细节。其解码流程分为两步:先由 ViT 像素解码器还原空间结构,再由流匹配细化器补充纹理与高频信息。对于音频,采用 Whisper 编码器提取语义特征,经下采样与 RVQ 后压缩为离散音频 token;解码端则先恢复梅尔频谱、再细化声学保真度,从而实现高质量合成与克隆,且支持方言口音鲁棒识别。
模型内部采用“模态无关的混合专家网络”作为主干路径,消除了传统拼接式多模态架构中冗余分支,将输入转化为统一 token 后仅需单一路线完成自回归预测。在推理与生成结合层面,团队提出串行与并行两种策略:串行生成依靠文本引导确保逻辑连贯性,而并行生成则引入延迟采样增强实时响应能力,并辅以 AS/AE/TE 特殊标记控制模态同步;其“V-Half 流水线调度”基础设施进一步解决了异构计算负载不均问题,显著减少通信开销与算力气泡。
实验表明,该模型在处理密集图文文档时仍能精准完成 QA 与逻辑推理,印证其离散表示具备极强语义完备性。针对强化学习中的熵爆炸问题,研究者设计序列级过滤机制有效遏制噪声累积。未来工作重点在于提升高压缩率下的语义保全性及长序列任务稳定性。最终,论文提出的“柏拉图表征假说”指出:当文本、图像与声音被置于同一离散原生框架内,它们便不再是割裂表征,而成为表达同一底层现实的“世界语言”,这是迈向真正通用多模态智能的关键一步。
LongCat-Next 是目前首个在纯离散框架下,将上述细粒度视觉理解能力推至与专用连续模型相当水平的统一多模态模型;在同等 token 预算下,理解与生成的联合训练不仅没有相互拖累,理解任务的训练信号反而对生成质量有正向促进;视觉和文本 token 的特征分布自然地交织在了一起,它们不再是需要被强行对齐的异类,而是变成了表达同一个底层概念的「世界语言」。
原文和模型
【原文链接】 阅读原文 [ 5502字 | 23分钟 ]
【原文作者】 机器之心
【摘要模型】 qwen3-vl-flash-2026-01-22
【摘要评分】 ★★★★★


相关文章


