文章摘要
【关 键 词】 扩散模型、搜索代理、推理加速、多跳问答、性能提升
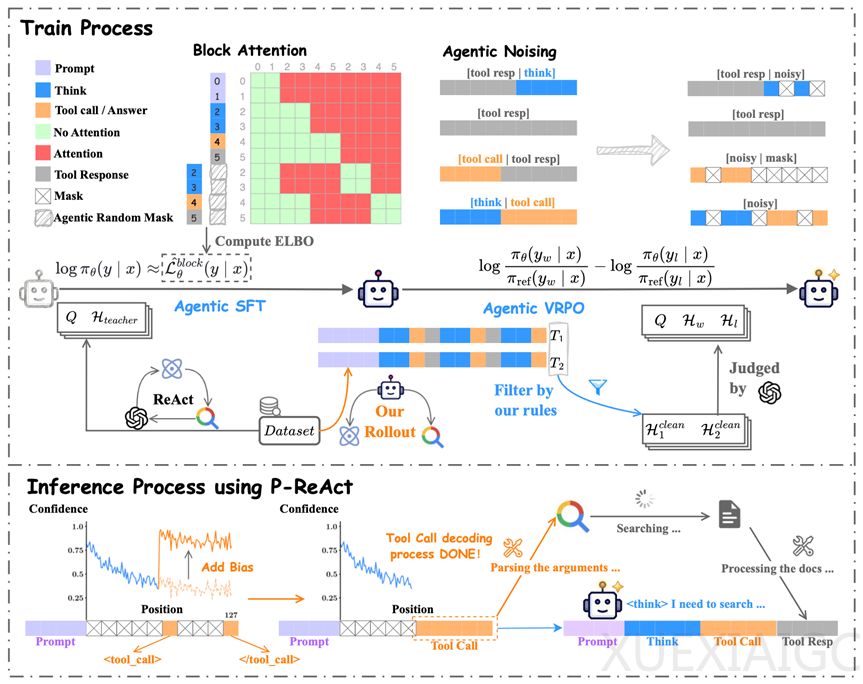
传统搜索Agent普遍采用ReAct框架,执行流程为严格串行的想→调工具→等结果→再想→再调工具→再等……,每轮“思考”与“调用工具”环节完全串行,等待搜索引擎返回结果时模型全程闲置,多轮叠加后端到端延迟大幅增加,严重拉低用户体验。自回归模型因因果注意力限制,无法在等待时并行思考,调整输出顺序会导致准确率显著下降,难以破解串行等待难题。
扩散语言模型天生能实现“一心二用”,其核心优势在于并非从左到右逐个生成token,而是所有位置同时“去噪”逐步浮现完整文本,生成顺序自由且在解码前已具备潜在推理信息。但原始扩散大语言模型(dLLM)直接作为搜索Agent效果极差,在HotpotQA测试中成功率为0%,因格式错误、未调用工具等问题全部失败,说明其虽有并行潜力,却缺乏推理和工具调用能力。
研究团队设计两阶段训练流程解决这一问题:第一阶段通过Agentic SFT,利用豆包Seed-1.8生成的高质量轨迹,结合Agentic Noising和Agentic ELBO损失函数,让dLLM精准学习推理与工具调用逻辑,避免训练时的信息泄露;第二阶段Agentic VRPO筛选答对与答错的轨迹对进行偏好优化,使所有数据集准确率提升3个百分点以上。
在此基础上,团队提出无需额外训练的P-ReAct推理加速方案:通过预填充边界标记指定工具调用区域,并对该区域置信度加正偏置,让模型优先解码工具调用并发送给搜索引擎,同时在等待结果时继续填充思考部分,实现“先动手、后想明白”,带来14.77%到22.08%的端到端推理加速且性能几乎无损失。
最终,DLLM-Searcher在四个多跳问答基准上平均准确率达57.0(ACC_R)/56.6(ACC_L),全面超越传统RAG方法,与自回归搜索Agent R1Searcher持平甚至小幅领先,且仅用不到8000条训练数据就在域外数据集Bamboogle上取得68.8的高分,泛化能力强劲。这一成果证明经针对性训练的dLLM可追上自回归模型的推理能力,还能凭借并行生成优势实现等待时持续思考,为搜索Agent效率优化开辟了全新路径。
原文和模型
【原文链接】 阅读原文 [ 2079字 | 9分钟 ]
【原文作者】 量子位
【摘要模型】 doubao-seed-1-8-251228
【摘要评分】 ★★★★★


相关文章


