文章摘要
【关 键 词】 自我进化、强化学习、信号挖掘、异步架构、策略蒸馏
普林斯顿大学研究团队提出的OpenClaw-RL框架,旨在实现智能体通过日常交互实现持续自我进化,其核心在于将原本被丢弃的用户反馈与环境响应转化为可训练的信号。该框架将实时交互数据划分为两类关键信号:评价性信号与指令性信号。前者如用户追问、代码测试结果或错误日志,构成隐式的对错判断;后者则包含明确修改建议,例如用户指出“不该使用某某函数库”或报错日志中的逻辑线索,为模型提供Token级的修正方向。研究指出,当前主流训练方式过度依赖昂贵的人工标注与静态数据集,而OpenClaw-RL直接利用自然产生的动态交互流,显著降低训练成本并提升数据时效性。
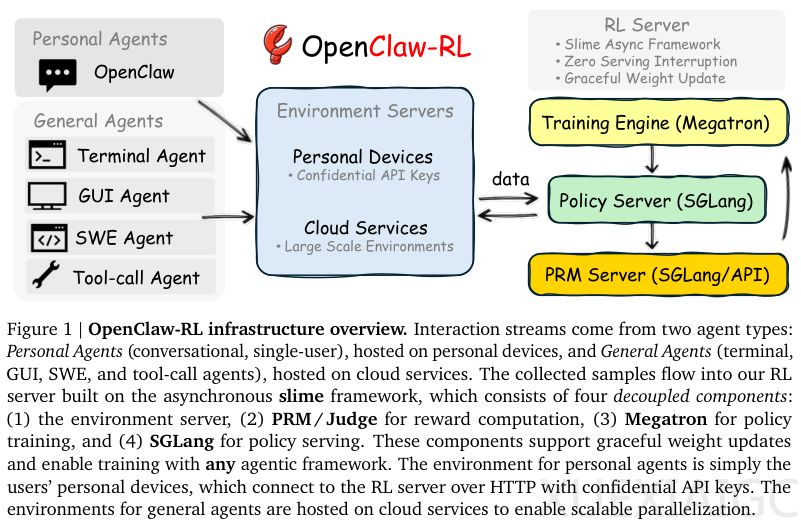
为保障用户体验不受影响,系统采用完全解耦的异步架构,基于开源框架slime构建四大独立循环模块:推理引擎、环境运行节点、过程奖励模型与策略训练引擎。其中,推理服务由SGLang驱动以保证对话流畅性;过程奖励模型在后台同步分析刚发生的对话;Megatron引擎则依据累积梯度更新模型权重;所有模块并行运行,互不阻塞。数据采集采用无阻塞日志机制,写入操作异步触发,且日志在每次权重更新后自动清理,确保训练数据与当前策略版本严格同步。该设计既支持部署于个人设备端以满足定制化需求,又兼容云端大规模算力,适配包括图形界面操作、软件工程测试及工具调用在内的多类真实场景。
在信号转化层面,框架融合两套互补机制:二元强化学习机制处理评价性信号,通过多数投票构建裁判模型,输出±1或0的离散分值;后见之明引导的在线策略蒸馏则专注于指令性信号,从用户回复中提取长度超10字符、信息量充足的操作指南,并将其拼接到上一轮输入末尾,形成增强版教师上下文,从而计算Token级对数概率差异,实现高精度微观修正。二者在数学层面加权叠加:前者提供广泛梯度覆盖,后者贡献高分辨率指导。针对长周期任务,系统引入分步奖励机制,由过程奖励模型对每个操作步骤独立评分,保障训练稳定性。
实验验证部分设置了两条平行轨道:个人智能体轨道模拟学生写作业与教师批改场景,设定低学习率与每16样本触发一次更新;通用智能体轨道则部署40亿至320亿参数模型,在代码、GUI与工具调用任务中进行强化学习扩展。结果显示,混合优化方法效果最优:学生场景下仅36次互动即消除机器表达痕迹;教师批改场景中24次互动后评语即具备具体性与人情味;云端测试中,过程奖励与最终结果奖励相融合的混合打分模式全面超越单一结果导向模式,证实了其在长线任务中的准确度优势。最终,OpenClaw-RL证明:无需人工干预,仅凭日常对话交互,即可驱动智能体实现全自动、渐进式自我进化。
原文和模型
【原文链接】 阅读原文 [ 2751字 | 12分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 qwen3-vl-plus-2025-12-19
【摘要评分】 ★★★★☆


相关文章


