谢赛宁REPA得到大幅改进,只需不到4行代码
文章摘要
【关 键 词】 表征对齐、全局信息、空间结构、扩散模型、视觉编码器
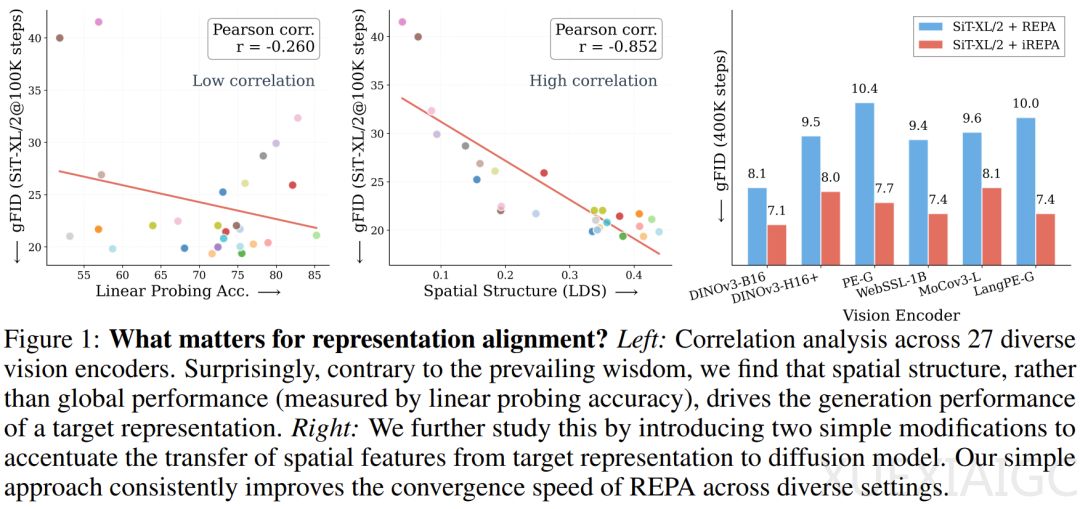
反直觉的发现颠覆了传统认知:驱动生成模型性能的关键因素并非预训练视觉编码器的全局语义信息(如ImageNet分类准确率),而是其提取的空间结构特征。一项由Adobe Research、澳大利亚国立大学和纽约大学联合开展的大规模实证研究表明,图像块(patch)token之间的成对余弦相似度——即空间自相似性(Spatial Self-Similarity)——与生成质量的皮尔逊相关系数高达0.852,而传统线性探测准确率的相关性仅为-0.260。这一结论通过27种视觉编码器的测试得到验证,例如分割模型SAM2-S虽分类准确率仅24.1%,但其指导生成的FID分数优于准确率高出60%的PE-Core-G模型。
空间结构主导性的量化分析揭示了生成模型的底层机制。研究团队提出局部与远距相似性(LDS)指标,发现保留”近亲远疏”空间关系的编码器能显著提升生成效果。这种特性解释了三个关键反例:分类性能平庸的SAM2模型因擅长捕捉轮廓信息而表现优异;同一模型家族中参数量更大的版本(如DINOv2-g)反而可能降低生成质量;强制融合全局信息的CLS token会导致FID分数恶化。这些现象共同指向空间结构对生成任务的本质重要性。
基于这一发现,研究者提出了改进方案iREPA,其核心创新包含两个部分:用3×3卷积层替代MLP投影层以保留局部空间关系,以及引入空间归一化层消除干扰生成的全局均值信息。尽管代码实现不足4行,该方法在多项实验中展现出显著优势。在扩散Transformer(SiT-XL/2)训练中,iREPA使各种视觉编码器的收敛速度平均提升22.2%-39.6%,且模型规模越大收益越明显。测试涵盖监督学习(DeiT)、自监督学习(DINOv2)和多模态模型(CLIP)等27种编码器,FID分数均实现稳定下降。
iREPA的泛化能力体现在与现有技术的无缝集成。无论是像素空间扩散(JiT模型)还是先进训练方法(REPA-E、Meanflow),加入空间结构优化后均能获得额外性能提升。可视化对比显示,经iREPA处理的特征图语义边界更清晰,生成的图像在物体轮廓和纹理细节上具有肉眼可见的改善。例如在动物类别样本中,公鸡羽毛层次感和鱼类鳞片纹理的连贯性显著增强。
这项研究从根本上改变了表征对齐领域的技术路线选择标准。空间结构指标相比传统分类准确率能更可靠地预测编码器在生成任务中的表现,这一发现为后续研究提供了明确方向。团队开源的方法以其简洁性和普适性,有望成为扩散模型训练的标准组件,推动生成式AI技术效能的整体提升。
原文和模型
【原文链接】 阅读原文 [ 2665字 | 11分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章


