文章摘要
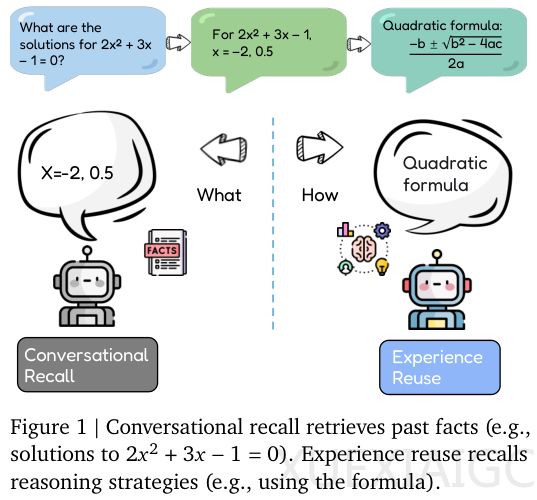
Evo-Memory框架的提出标志着大型语言模型从被动检索迈向主动经验复用的关键突破。该框架由谷歌DeepMind与伊利诺伊大学联合开发,通过测试时自我进化机制,使智能体能够在持续任务流中实现真正的终身学习。传统大模型虽具备长上下文记忆能力,但仅能静态回溯对话内容,无法将具体经验提炼为通用方法论。这种缺陷导致智能体每次面对相似任务时都需从零开始,如同”过目不忘的初学者”永远无法进阶为专家。
研究团队构建的Evo-Memory基准测试颠覆了传统静态评估模式,将数据集重构为流式任务链,模拟真实世界连续发生的场景。智能体被要求在处理当前任务时动态维护不断演进的记忆库,形成包含基础模型、记忆更新机制、检索模块和上下文构造机制的四元组架构。基准测试涵盖十大高难度数据集,分为单轮推理(如数学奥赛题AIME系列)和多轮交互(如家庭环境模拟AlfWorld)两大类型,全面检验智能体在符号逻辑、工具使用及环境适应等方面的能力。
ReMem架构作为核心创新,通过引入”思考-行动-记忆提炼”的三元操作闭环,实现了对记忆的主动管理。与传统ExpRAG基线相比,ReMem不仅能存储结构化经验,更能通过Refine操作回溯推理轨迹,识别关键转折点并删除误导性信息。实验数据显示,在Gemini 2.5 Flash模型上,ReMem使单轮任务平均准确率提升至0.65;在AlfWorld环境中,任务完成步数从基线22.6步压缩至11.5步,证明经验复用可显著减少无效探索。
深入分析揭示任务相似度与记忆效能的正相关关系。在PDDL等结构化程度高的任务中,ReMem表现最佳;而面对GPQA等多变逻辑问题时提升幅度较小。意外发现是先难后易的任务序列能促使智能体生成更抽象的策略,形成对简单任务的”降维打击”效果。此外,ReMem对失败经验的处理独具特色——将错误转化为约束条件而非简单记录,这种负面反馈的消化机制保障了进化稳定性。
随着任务量增加,ReMem的累积成功率曲线与基线差距持续扩大,尤其在ScienceWorld环境中展现出明显的震荡上行趋势。这表明智能体的学习具有累积性,其进化过程符合”越用越强”的特征。该研究为终端设备部署轻量级进化模型提供可能,同时重新定义了记忆在人工智能中的角色——不仅是信息存储介质,更是动态认知加工的载体。
原文和模型
【原文链接】 阅读原文 [ 3555字 | 15分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章


