文章摘要
【关 键 词】 大模型、深度研究、智能体、成本优化、数据策略
训练管线采用三阶段渐进式设计:代理式中间训练聚焦32K-128K上下文长度下的原子能力培养;监督微调阶段连接孤立能力形成端到端任务处理链条;强化学习阶段通过细则判断模型实现多维优化。中间训练首次实现128K超长上下文下的工具增强推理,使模型掌握网页浏览、多工具协作等复杂操作逻辑。强化学习采用基于细则的PPO算法,通过专业构建的Rubrics Judge模型提供精准奖励信号,并引入工具调用预算控制等现实约束。
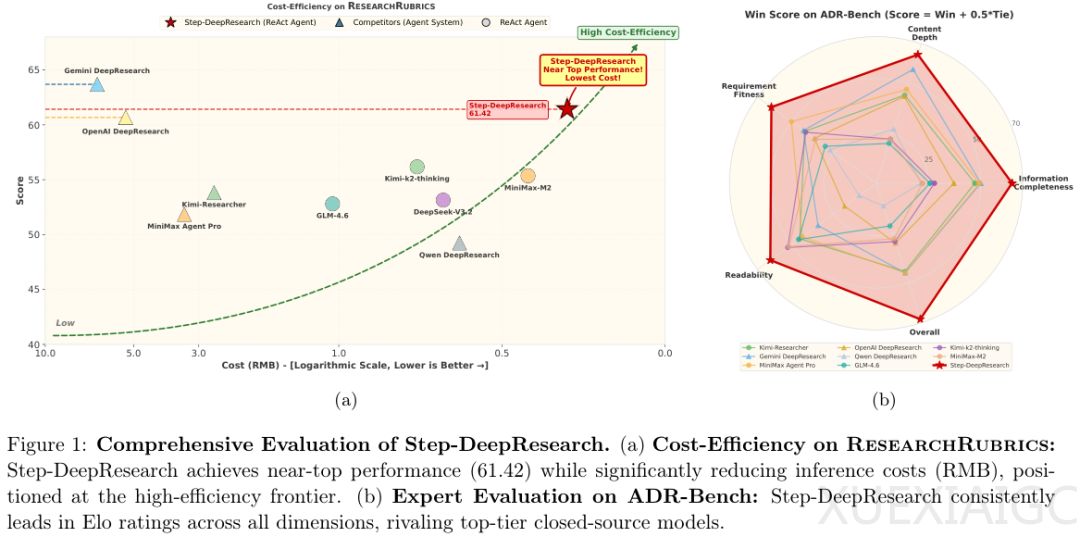
实战部署中,系统通过权威站点索引分片和段落级专业文献库解决信噪比问题,视觉冗余消除策略降低多模态Token消耗70%。在自建的中文深度研究基准ADR-Bench上,该模型以61.42分超越多数商业系统,成本仅为顶级模型的1/10。评估显示其在人工智能、历史分析等领域媲美Gemini,创意写作维度更达63.4分领先水平。专业领域测试中,尽管面临严格负面评分,仍稳居第二梯队。
该成果验证了精细化训练方案可使中等参数模型突破规模限制,但工具泛化性、长任务鲁棒性等挑战仍需突破。团队特别指出,当前行业基准测试与真实效用存在鸿沟,而Step-DeepResearch通过应用驱动的评估体系,为深度研究智能体的实用化提供了新范式。
原文和模型
【原文链接】 阅读原文 [ 4623字 | 19分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★☆☆☆

© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章

暂无评论...

