文章摘要
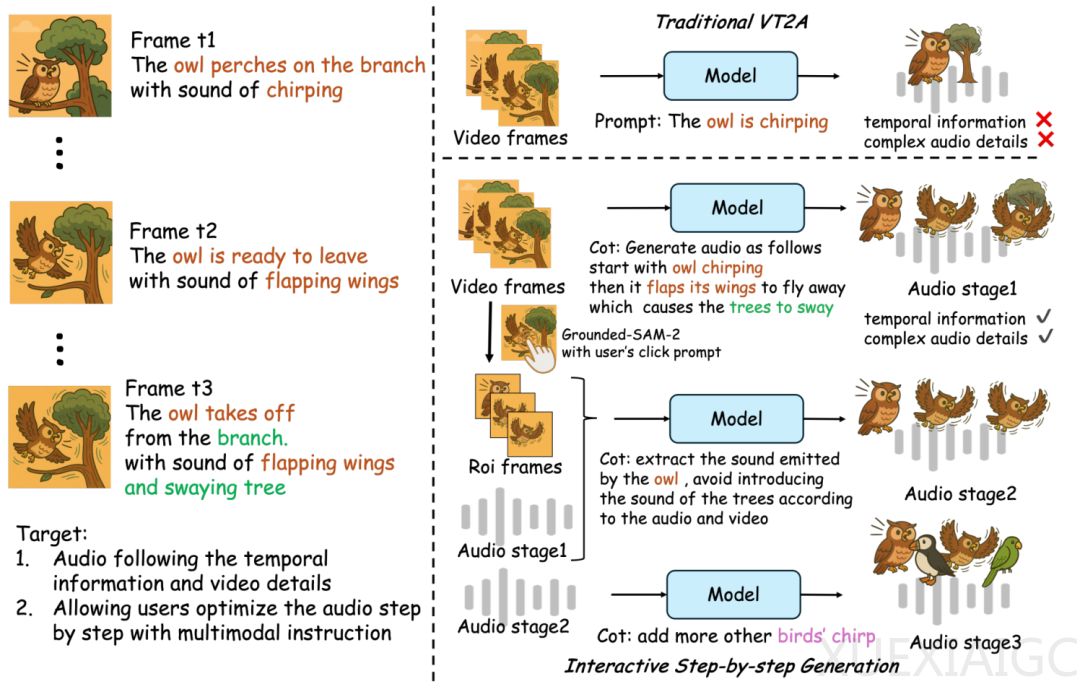
阿里通义语音团队最新开源的泛音频生成模型ThinkSound,首次将CoT思维链推理引入音频领域,解决了传统视频配乐技术难以捕捉画面动态细节和空间关系的难题。ThinkSound通过模仿人类音效师的多阶段创作流程,精准建立起声音和画面之间的对应关系,显著提升了音画同步的真实感与同步性。该模型在业界知名的音视频数据集VGGSound上,对比6种主流方法,在核心指标上均实现了显著提升。
ThinkSound的音频生成过程分为三个阶段:基础音效推理链构建、面向交互的对象级推理链构建和基于指令的音频编辑推理链构建。通过多模态大语言模型和基于流匹配的统一音频生成模型,ThinkSound能够同时理解视频画面、文字描述和声音上下文,逐步生成真实自然的音效。此外,团队还构建了链式音频推理数据集AudioCoT,确保模型真正实现音画同步。
在实验中,ThinkSound不仅在VGGSound上超越6种主流音频生成方法,还通过消融实验验证了推理链对音频生成质量的重要性。将CLIP的视觉特征和T5的文本推理结合起来,能进一步优化音频的理解和表现,而门控融合机制在各项指标上均表现最优。阿里通义语音团队在语音生成领域的一系列动作,已在开源社区占据了一席之地,ThinkSound的发布进一步巩固了其在该领域的领先地位。
ThinkSound的推出,标志着AI音效生成技术迈入了一个新阶段。通过引入CoT思维链推理,模型能够更精准地捕捉视觉动态和声学属性,生成与环境相符的高保真音效。这一技术的应用,不仅提升了视频配音的质量,也为音频生成领域带来了新的可能性。
原文和模型
【原文链接】 阅读原文 [ 2642字 | 11分钟 ]
【原文作者】 量子位
【摘要模型】 deepseek-v3
【摘要评分】 ★★★★☆


相关文章


