文章摘要
【关 键 词】 智能运维、大模型、基准测试、故障排查、开源模型
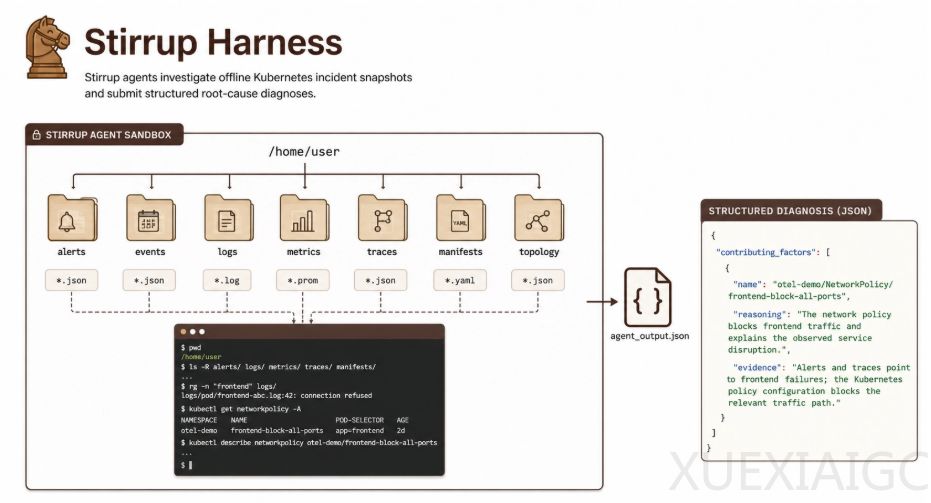
Artificial Analysis与IBM联合推出了首个专门针对企业级IT任务的智能体基准测试ITBench-AA,旨在填补现有通用评测标准在高度专业化的企业运维领域的空白。该基准首期聚焦于站点可靠性工程师任务,后续将扩展至财务运营和信息安全方向。在真实的容器编排故障排查场景中,所有参与测试的前沿大模型得分均未超过50%,表明当前人工智能在处理复杂企业级运维任务时仍面临巨大挑战。
该测试包含59道贴近真实业务的排障题目,要求模型通过分析告警、日志、链路追踪等数据,精准定位导致故障的最小独立根因实体集合。评测采用全召回条件下的平均精度作为严格的评分规则,漏报真实根因将直接导致该次得分归零,而多报或误报则会降低精确率。这种机制真实反映了企业运维中对故障定位准确性和效率的严苛要求,迫使模型在准确和全面之间做出取舍。
测试过程中的关键发现揭示了排查策略对最终结果的显著影响。对话轮次较多、过度调查的模型往往因为将并发症状或注入机制误认为根因提交,导致误报率上升和最终得分下降,这证明在运维排障中精准定位根因远比盲目增加调查轮次更为重要。这一结论对智能体的设计思路具有直接启发,强调了干净利落提交确信答案的价值,避免了因过度排查而产生的资源浪费与误判风险。
在模型成本与性能的权衡方面,开源模型展现出了极高的性价比。尽管闭源模型在绝对得分上占据前列,但部分开源模型在单题成本远低于闭源模型的情况下,取得了相当甚至更高的分数,为企业在大规模部署智能体时提供了更具经济效益的选择。随着未来更多专业领域任务的加入,该基准测试将为评估人工智能在不同企业IT管理场景下的差异化表现提供更全面的参考依据。
原文和模型
【原文链接】 阅读原文 [ 2534字 | 11分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 qwen3.7-max
【摘要评分】 ★★★★★


相关文章


