文章摘要
【关 键 词】 AIGC领域、3D重建、iLRM模型、注意力机制、模型训练
AIGC领域聚焦大语言模型发展与应用落地,而在3D建模方面,基于前馈网络的方法受关注,但多数基于Transformer架构的模型处理多视图输入时存在可扩展性问题,计算成本随视图数量或图像分辨率增加呈二次方增长。为此,成均馆大学、延世大学研究人员提出创新3D重建模型iLRM。
iLRM遵循三大核心原则:解耦场景表示与输入图像实现紧凑三维表示;将全注意力多视图交互分解为两阶段注意力方案减少计算成本;在每一层注入高分辨率信息实现高保真重建。
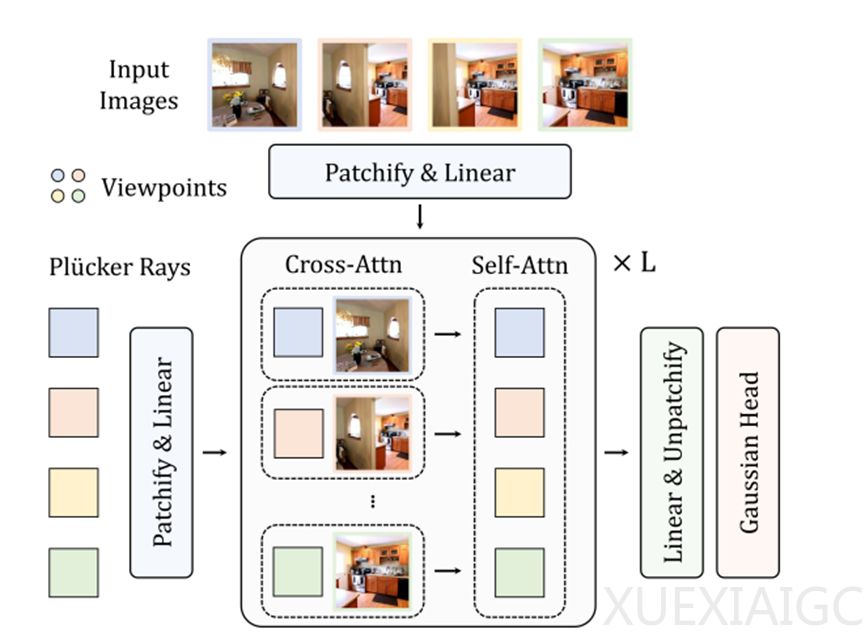
在架构设计上,起始阶段采用视点标记化模块。利用Plücker射线嵌入表示输入视图几何信息,将其划分为非重叠块并重塑为一维向量生成紧凑视点标记集合,经线性层编码提供高效初始表示。处理输入图像时采用多视图图像标记化,将输入图像视觉信息与视点标记融合,生成包含视觉和相机姿态信息的图像标记,提高重建准确性和细节表现。
在多视图上下文建模方面,提出高效两阶段注意力机制。将多视图交互分解为交叉注意力和自注意力,交叉注意力阶段一对一交互计算效率高,自注意力阶段捕捉不同视图依赖关系,降低计算复杂度并保留全局信息交互能力。
iLRM核心的更新块是迭代细化机制,由多个Transformer模块组成。引入标记提升策略,解决视点标记和图像标记分辨率差异问题,更好捕捉视觉对应关系。还提出小批量交叉注意力机制,通过选择性采样图像和视点标记降低交叉注意力计算复杂度。
训练阶段,通过最小化重建图像与真实图像的均方误差和感知损失优化模型参数,兼顾像素级准确性和视觉质量。多层迭代更新后,将最终视点标记解码为三维高斯参数用于渲染目标视图图像,实现高质量三维重建。
原文和模型
【原文链接】 阅读原文 [ 1775字 | 8分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 doubao-1-5-pro-32k-250115
【摘要评分】 ★★★★☆


相关文章


