文章摘要
在2003年,计算机架构师迈克尔·J·弗林(Michael J. Flynn)提出了一个关于计算未来的重要警告。他指出,CPU的复杂化趋势——如推测执行、深度流水线和臃肿的指令处理——已经难以为继。弗林预测,未来的计算将不再依赖复杂的通用处理器,而是转向简单、并行、确定性和领域特定的设计。二十年后,随着推测执行漏洞的暴露和人工智能加速器的兴起,弗林的预言得到了验证。他的理念在谷歌、NVIDIA、Meta等行业巨头以及新兴企业如Simplex Micro的设计中得到了体现。
弗林对推测执行的批评早于2018年Spectre和Meltdown漏洞的爆发,这些漏洞暴露了推测执行的安全隐患。推测执行虽然提升了性能,但代价高昂,包括功耗、验证工作量以及安全性问题。弗林认为,推测执行是一种脆弱的优化,会引发深度设计颠覆,使形式验证更加困难,并且功耗与其性能提升不成比例。如今,芯片制造商如英特尔正在重新思考其架构优先级,优先考虑效率而非激进的推测,并针对每瓦吞吐量进行优化。苹果的M系列芯片也强调可预测的延迟和编译器主导的优化,而非纯粹的推测深度。
在嵌入式领域,Arm的Cortex-M和Neoverse产品线趋向于简化的流水线和明确的调度,通常会完全放弃推测逻辑以满足实时性和功耗限制。开放的RISC-V生态系统使新一代CPU和加速器设计人员能够从第一原理出发进行构建,通常无需任何推测。Simplex Micro等供应商正在倡导确定性、低开销的执行模型,利用向量和矩阵扩展或预测调度来取代推测。这些选择直接体现了弗林的论点:当正确性、性能和可扩展性比峰值IPC更重要时,简洁性将胜出。
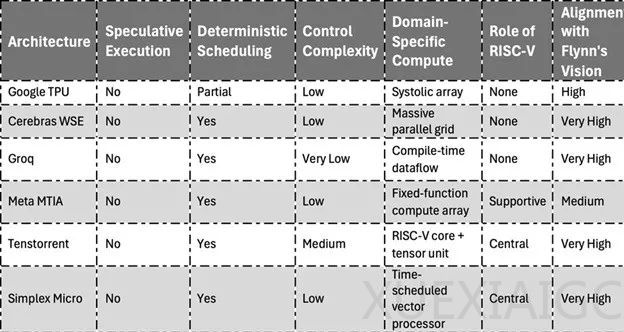
在人工智能加速器的兴起中,弗林的愿景得到了最生动的体现。从谷歌的张量处理单元(TPU)到英伟达的张量核心,从Cerebras的晶圆级引擎到Groq的数据流处理器,趋势显而易见:抛弃推测复杂性,转而拥抱大规模并行、确定性计算。谷歌的TPU通过脉动阵列处理矩阵运算,实现了高吞吐量和确定性延迟。Cerebras Systems的晶圆级引擎将数十万个处理元件集成到单个晶圆大小的芯片上,优化了数据局部性和可预测性。Groq围绕编译时调度数据流构建芯片,具有极强的确定性,所有执行路径均已预先定义,消除了推测逻辑的时序可变性和设计复杂性。
Meta在其定制的MTIA(元训练和推理加速器)芯片中融入了弗林式的思维,这些处理器专为推荐系统等推理工作负载而设计,强调可预测的吞吐量和能效,而非纯粹的灵活性。弗林还预测计算将分裂成领域特定架构(DSA),这一预测已成为现代硅片设计的基础。如今的硬件生态系统充满了DSA,包括人工智能专用处理器、网络和存储加速器、以安全为中心的微控制器和超低功耗边缘SoC。这些架构去掉了不必要的功能,最大限度地降低了控制复杂性,并专注于在给定领域内最大限度地提高每瓦性能。
弗林在2003年传递的信息非常明确:复杂性不可扩展,而简单性才可扩展。如今,从TPU到RISC-V矢量处理器等领先的架构都采用了这一理念,但往往没有明确提及弗林奠定的基础。数据流架构、显式调度和确定性流水线的复兴表明,业界终于开始倾听他的呼声。在这个安全性、能效和实时可靠性比以往任何时候都更重要的时代,弗林对后推测计算的愿景不仅具有现实意义,而且至关重要。他是对的。
原文和模型
【原文链接】 阅读原文 [ 2210字 | 9分钟 ]
【原文作者】 半导体行业观察
【摘要模型】 deepseek-v3
【摘要评分】 ★★★★★


相关文章


