2M大小模型定义表格理解极限,清华大学崔鹏团队开源LimiX-2M
文章摘要
【关 键 词】 AI模型、结构化数据、深度学习、轻量化、性能突破
在AI领域,大语言模型(LLM)虽在非结构化数据处理上表现卓越,却在结构化表格数据建模中长期难以超越传统梯度提升方法。这一现象引发了关于深度学习在结构化数据领域局限性的讨论。清华大学崔鹏团队开发的LimiX模型,特别是其轻量级版本LimiX-2M,通过仅2M的参数量,在分类、回归和缺失值插补等任务中展现出超越XGBoost、CatBoost等经典模型的性能,并在与AutoGluon和TabPFN的对比中取得显著优势。
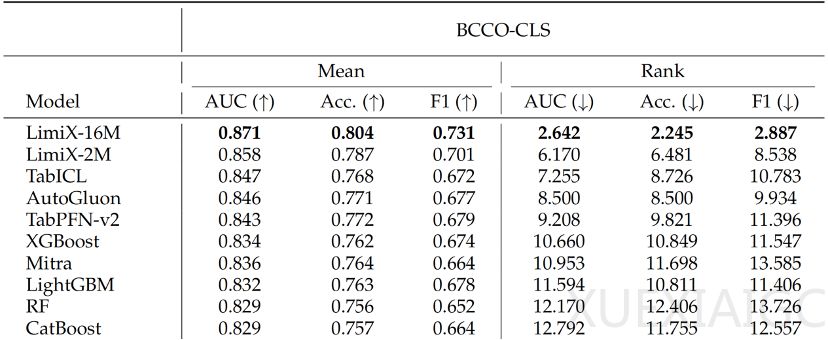
LimiX-2M的核心创新在于其RBF嵌入层(RaBEL),通过引入非线性表达能力,解决了传统线性嵌入的“低秩塌陷”问题。这一设计使模型在浅层即可识别非平滑关系,显著提升了特征表示的丰富性和多样性。实验数据显示,LimiX-2M在11个权威评测基准上的平均性能仅次于其前代LimiX-16M,位列第二。在BCCO-CLS和CTR23等基准数据集上,LimiX-16M和LimiX-2M包揽分类任务前两名,回归任务中LimiX-16M稳居榜首,LimiX-2M位列第三。这些成绩均在无需任务特定微调的“开箱即用”模式下达成。
LimiX-2M的轻量化设计使其在资源消耗和部署灵活性上具有显著优势。该模型可在消费级显卡RTX4090上完成微调,而同类模型如PFN-V2.5需要更大显存的显卡。微调实验表明,LimiX-2M在analcatdata_apnea2数据集上的AUC提升11.4%,所需时间仅为PFN-V2.5的60%。这种高效性使LimiX-2M成为科研和工业应用的理想选择,尤其适合算力有限的小型团队和高合规要求的场景。
LimiX模型的开源标志着中国在表格建模领域的研究达到世界领先水平。其技术特点包括:基于上下文学习的开箱即用能力、单模型支持多任务的灵活性、小样本场景下的高效泛化、通过检索机制提升模型可解释性,以及完全离线运行的隐私保障。这些特性使其在医疗、生物、国防等领域具有广泛的应用潜力。
LimiX的成功不仅体现在性能指标上,更在于其推动科研创新的方法论价值。通过降低技术门槛,该模型让研究人员能够专注于科学问题本身,而非受困于算力或工程难题。其轻量化设计和高效性能的平衡,为AI技术在现实世界中的落地提供了新的可能性,特别是在资源受限的环境下。这一突破或将重新定义结构化数据建模的标准,并为通用智能的发展开辟新的路径。
原文和模型
【原文链接】 阅读原文 [ 2468字 | 10分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章


