文章摘要
【关 键 词】 AI模型、视觉语言、细粒度理解、双语对齐、技术创新
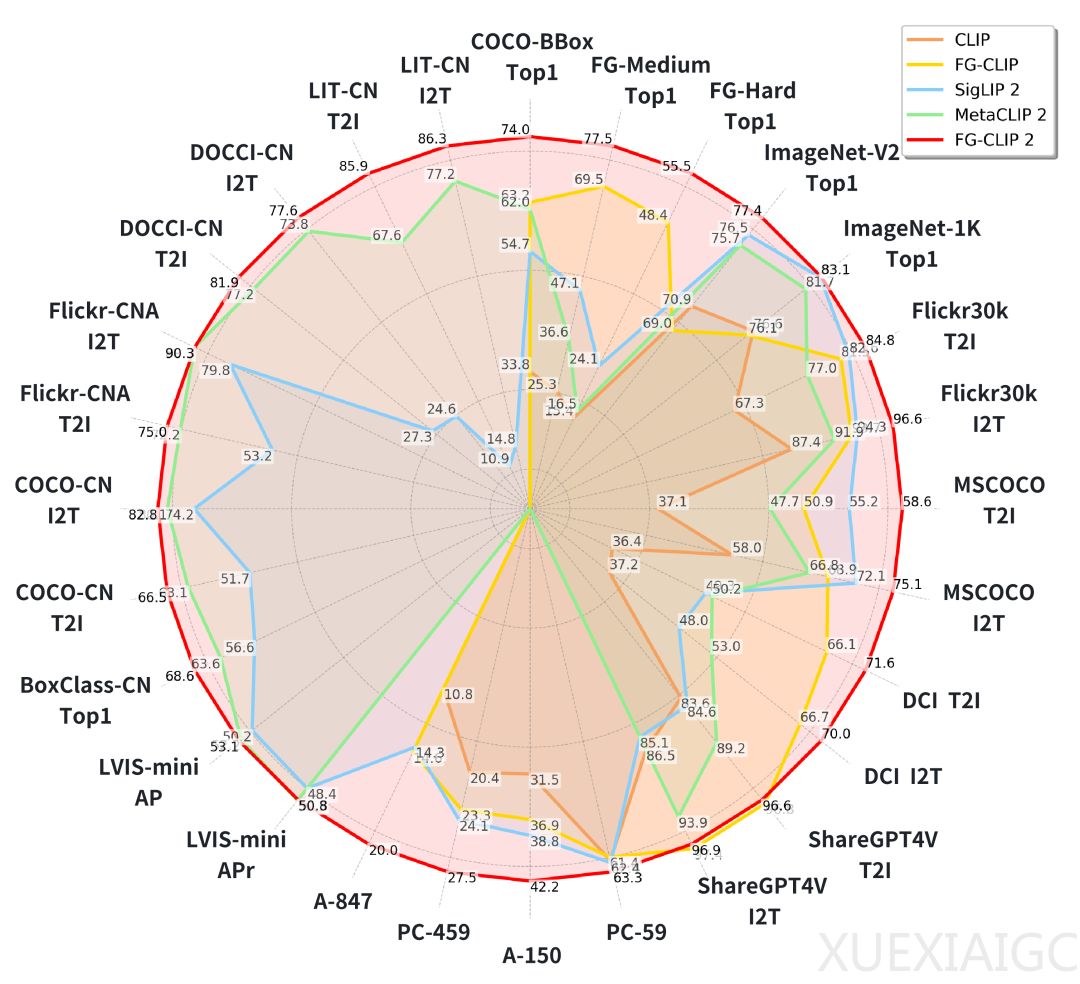
360 AI Research团队推出的FG-CLIP 2模型在视觉-语言对齐领域实现了重大突破,首次在统一框架内同时解决细粒度理解和双语对齐两大挑战。该模型通过分层学习框架和四项核心技术,在8类任务、29个数据集的测试中全面超越现有模型,尤其在中文环境下表现突出。其创新架构包含两阶段训练:第一阶段建立全局语义对齐,第二阶段通过细粒度视觉学习、文本学习、跨模态排序损失和文本模态内对比损失四项技术,实现从粗到精的渐进式优化。
FG-CLIP 2的核心突破在于解决了传统CLIP模型的两大局限:对图像细节的忽视和英语语料的依赖。通过构建包含4000万区域边界框标注的双语数据集,模型能精确关联图像局部特征与对应文本描述。在细粒度OVD测试中,其ViT-L版本较前代提升7.1个百分点;在中文长字幕检索任务上更是以显著优势领先。值得注意的是,10亿参数的FG-CLIP 2在多项指标上超越18亿参数的Meta CLIP 2,体现了其训练范式的高效性。
技术实现上,模型采用动态分辨率处理和掩码注意力池化等创新设计。文本编码器支持196个词元的输入长度,配合Gemma分词器的25.6万词汇量,为双语处理奠定基础。四项专项技术中,文本模态内对比损失(TIC)通过强化语义相近描述的差异性,显著提升了文本编码器的精确度。跨模态排序损失则通过全局阈值同步机制,确保分布式训练中的判断标准一致性。
数据层面,模型整合了LAION-2B增强版、悟道等中英文数据集,总量达16亿图文对。独创的双字幕策略——结合原始短字幕与LMM生成长字幕,既保留语言多样性又丰富语义上下文。中文细粒度数据建设尤为关键,团队构建的BoxClass-CN包含6.6万区域-描述对,填补了中文评测空白。
该研究不仅推出高性能模型,更通过新建中文评测基准推动领域发展。三个长字幕检索数据集和首个中文区域分类基准,为后续研究提供更精准的评估工具。未来方向包括扩展文本处理长度和显式建模物体关系,这将进一步深化多模态理解能力。FG-CLIP 2的突破表明,统一解决细粒度与多语言问题,是视觉-语言模型发展的有效路径。
原文和模型
【原文链接】 阅读原文 [ 4176字 | 17分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章


