400万人围观的分层推理模型,「分层架构」竟不起作用?性能提升另有隐情?
文章摘要
【关 键 词】 HRM模型、ARC验证、分层架构、外循环优化、预训练增强
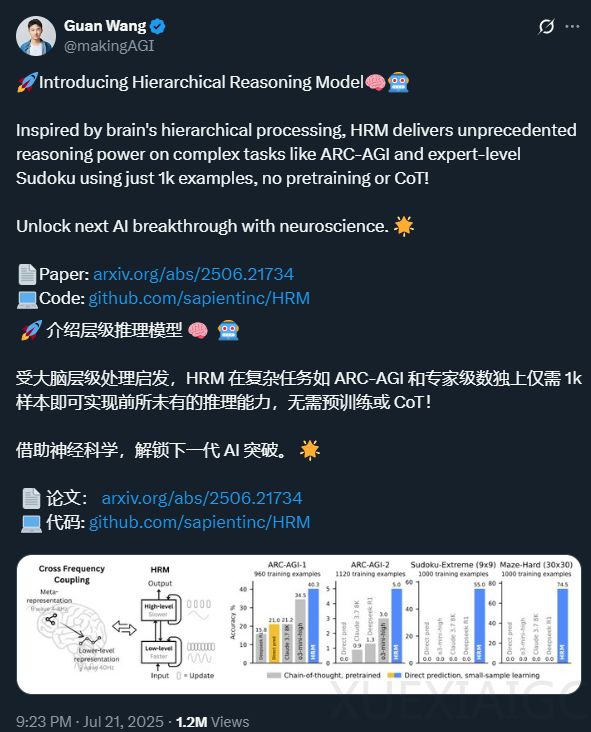
分层推理模型(HRM)于6月发布后引发广泛关注,ARC PRIZE团队对其在ARC – AGI – 1半私有数据集上的性能进行验证,并展开深入分析。
– HRM模型概述:HRM由新加坡AI研究实验室Sapient发表,受人脑机制启发,是一个2700万参数的模型。它通过迭代优化,每次脉冲产生预测输出网格和“停止或继续”得分。模型包含外循环和H – L两个耦合的循环模块,还采用任务增强和自适应计算机制。
– ARC – AGI验证结果:在ARC – AGI – 1(100个任务)上,HRM得分32%,运行时间9小时16分钟,总成本$148.50,虽未达SOTA水平,但对小模型而言表现出色;在ARC – AGI – 2(120个任务)上,得分2%,运行时间12小时35分钟,总成本$201,团队认为未取得有意义进展。
– 深入分析关键发现:
– 分层架构影响小:与同等规模的Transformer相比,HRM的“分层”架构对性能影响微乎其微,改变分层组件迭代次数或替换为Transformer,性能差异不大。
– 外循环优化作用大:论文中提及较少的“外循环”优化过程极大提升了性能,从无优化到1次优化,性能跃升13个百分点,且训练时优化比推理时优化更重要。
– 迁移学习益处有限:跨任务迁移学习益处有限,大部分性能来自对评估时特定任务解决方案的记忆,该方法本质上与“无预训练的ARC – AGI”方法相似。
– 预训练增强很关键:预训练的任务增强至关重要,仅300次增强就接近最大性能,且训练时使用数据增强比为多数投票获得更大池子更重要。
– 其他发现与待解决问题:HRM将ARC – AGI任务分解为谜题,依赖谜题嵌入层,但只能应用于训练时见过的puzzle_id。未来需探索puzzle_id嵌入影响、模型泛化能力、停止机制作用、优化思想推广、特定增强类型效果等问题。有人认为ARC PRIZE团队的分析是真正的“同行评审”,若更多采用此方式分析研究,社区能更高效获取知识。
原文和模型
【原文链接】 阅读原文 [ 5352字 | 22分钟 ]
【原文作者】 机器之心
【摘要模型】 doubao-1-5-pro-32k-250115
【摘要评分】 ★☆☆☆☆


相关文章


