5款大模型考「山东卷」,Gemini、豆包分别获文理第一名
文章摘要
【关 键 词】 大模型、高考测评、技术演进、多模态、推理能力
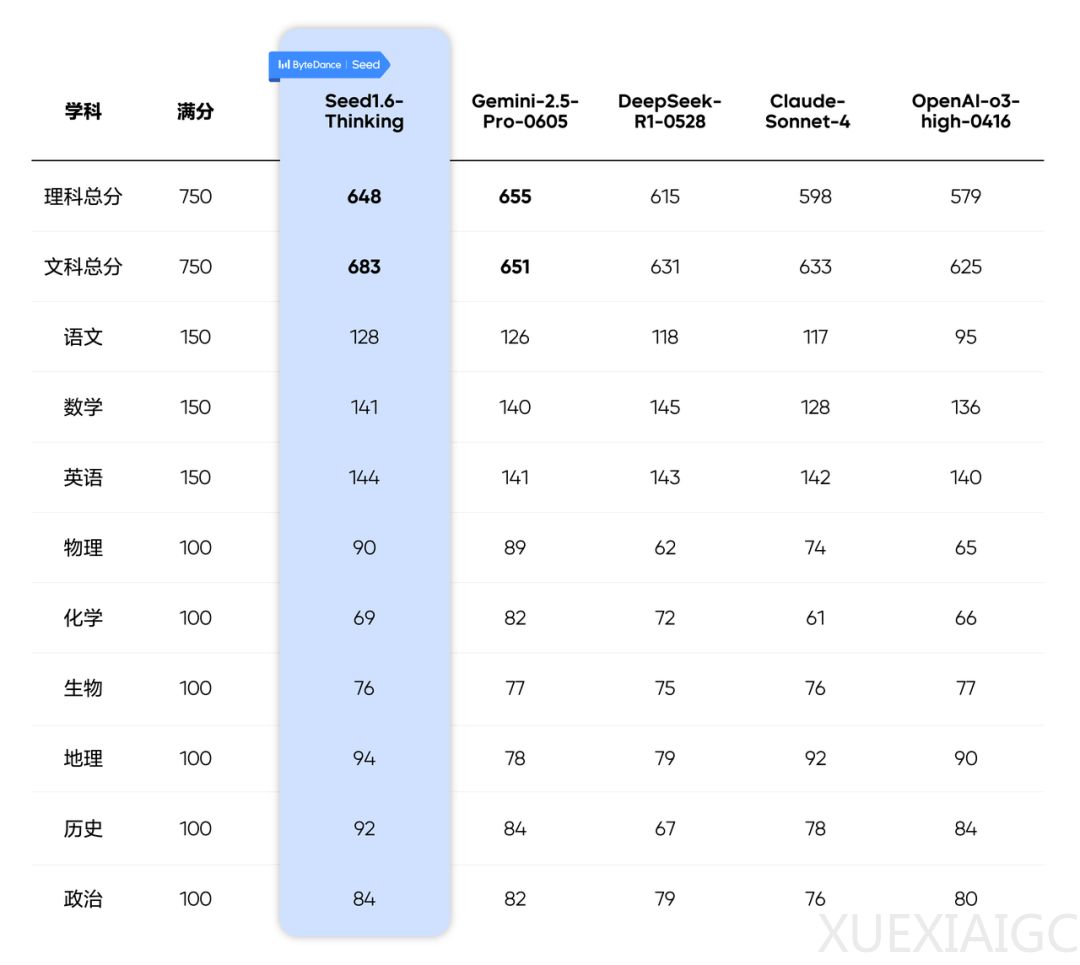
近期,5款主流大模型参与了2025年山东高考全科闭卷测评,结果显示AI的应试能力已实现质的飞跃。字节跳动Seed团队组织的测评采用750分制,未进行任何提示工程优化,所有输入均为高考原题。文科方面,豆包Seed 1.6-Thinking模型以683分位列第一,达到冲刺清华北大的水平;理科则由Gemini 2.5 Pro以655分领先,各模型文理科成绩均较去年提升超100分,实现从”普通本科”到”双一流”的跨越。
测评方法严格遵循高考判卷标准,选择题机判辅以人工质检,开放题由资深教师匿名评估。测试中,大模型在语数英基础学科表现优异,区分度较小,其中英语科目全员超过140分。但o3模型因作文跑题导致语文单科仅得95分,凸显当前AI在深度思辨和情感表达上的局限。数学科目进步显著,DeepSeek R1以145分居首,但各模型在含混合图像元素的第6题集体失分,暴露多模态理解的短板。
文综科目中,豆包以270分展现突出优势,地理和历史单科均突破90分,体现其对结构化资料的强大处理能力。理科方面,Gemini以248分领跑,但生物化学因图片清晰度问题影响得分,后续采用图文交织输入后,豆包生化成绩可提升30分,说明全模态推理能显著释放模型潜力。物理压轴题出现超纲解答现象,反映模型对解题限制的认知边界。
技术演进是成绩跃升的关键驱动。Gemini 2.5 Pro通过思维链实现深度推理,o3原生集成图像处理能力,豆包1.6-Thinking则采用三阶段预训练策略,支持256K上下文长度并融合视觉模态。Seed1.6-Thinking通过多轮RFT和RL迭代优化,在复杂问题上展现出更长的思考能力。这些创新使大模型逐步掌握题目背后的逻辑推演和跨模态理解。
随着AI在标准化考试中逼近人类顶尖水平,未来测试重点或将转向无标准答案的真实场景难题。大模型已展现出在科研、艺术等创造性领域的潜力,其发展轨迹预示着从”应试能手”向”生产力工具”的转型。技术突破的速度表明,高考作为AI能力基准测试的价值正在衰减,下一阶段应关注其解决开放性问题的实际应用能力。
原文和模型
【原文链接】 阅读原文 [ 3713字 | 15分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章


