6.1B打平40B Dense模型,蚂蚁开源最新MoE模型Ling-flash-2.0
文章摘要
【关 键 词】 Ling-flash、大模型、复杂推理、多场景应用、模型开源
蚂蚁百灵大模型团队正式开源最新 MoE 大模型 Ling-flash-2.0,该模型在多个权威评测中表现卓越,为大模型“参数膨胀”趋势提供新路径。
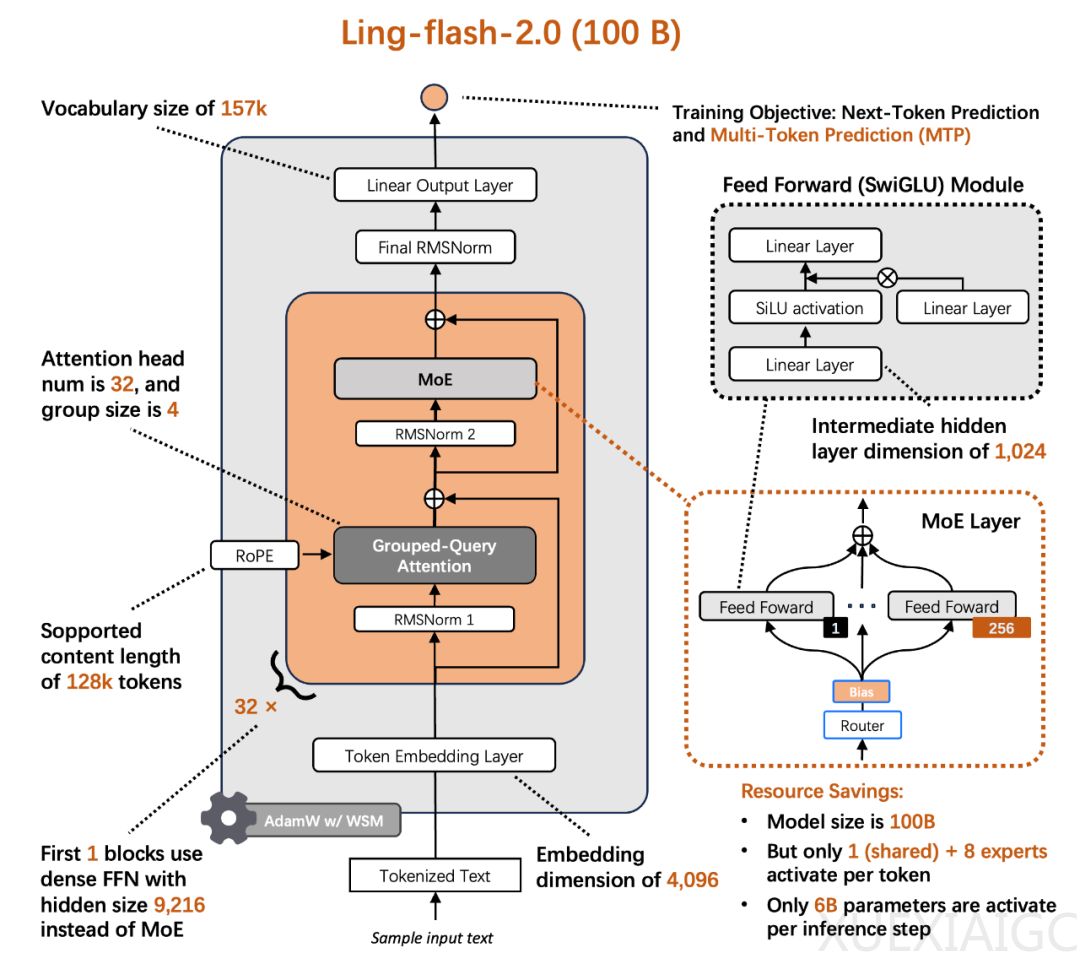
从“参数军备”到“效率优先”:当前大模型竞争中,“参数越多 = 能力越强”的公式失效,MoE 架构被寄予厚望。Ling-flash-2.0 从架构、训练到推理全栈优化,在仅激活 6.1B 参数的前提下超越 40B Dense 模型性能。团队通过 1/32 激活比例、专家粒度调优等策略,实现 7 倍以上性能杠杆,推理速度提升 3 倍以上。
强大的复杂推理能力:在多学科知识推理、高难数学、代码生成、逻辑推理、金融与医疗等专业领域评估中,Ling-flash-2.0 优于同级 Dense 模型和更大激活参数的 MoE 模型,尤其在高难数学推理、代码生成、前端研发任务中表现突出。
多场景应用能力:Ling-flash-2.0 在代码生成与编辑、前端研发、数学优化求解、CLI 接入等实际应用场景中展现强大能力,给出了多个具体用例展示。
高质量预训练基础:团队构建 AI Data System,完成 40T+ tokens 高质量语料处理,精选 20T+ tokens 用于预训练。预训练分三阶段,关键超参数由自研 Ling Scaling Laws 给出最优配置,还替换学习率调度器,扩展词表提升多语言能力。
后训练创新:团队设计四阶段后训练流程,包括解耦微调赋予模型解决实际问题能力,ApexEval 筛选潜力模型,演进式 RL 动态解锁推理能力,系统支撑保障训练质量。
Ling-flash-2.0 重新定义“效率”与“能力”关系,用 6.1B 激活参数证明模型智能在于架构、训练与推理协同优化。此次开源放出对话模型和 Base 模型,为研究者和开发者提供灵活使用空间,高效大模型时代已至,可在 HuggingFace、ModelScope、GitHub 开源仓库下载使用。
原文和模型
【原文链接】 阅读原文 [ 2855字 | 12分钟 ]
【原文作者】 机器之心
【摘要模型】 doubao-1-5-pro-32k-250115
【摘要评分】 ★★★★★


相关文章


