文章摘要
【关 键 词】 视频生成、面部逼真、物理真实、镜头语言、长时序
该模型在视频生成领域实现多项关键突破,显著提升内容真实感与创作自由度。
人物面部表情的处理达到新高度,眼神躲闪、嘴角微弧等细微动态被精准还原,使角色具备自然的情绪张力,这是此前主流模型难以企及的瓶颈突破。
物理真实性成为核心亮点:自行车拐弯时身体倾斜、头发飘动方向、车轮反光片闪烁节奏均符合物理规律,连沙尘飞溅方向与力度也高度一致。
镜头语言能力显著增强——无需具体提示词,模型能依据情节自动调度推拉摇移、特中远景切换与过肩反打等专业拍摄手法,有效传达情绪与叙事意图。
整体画面质感改善明显,成功弱化“塑料感”,尤其在面部特写与复杂动作场景中表现突出。
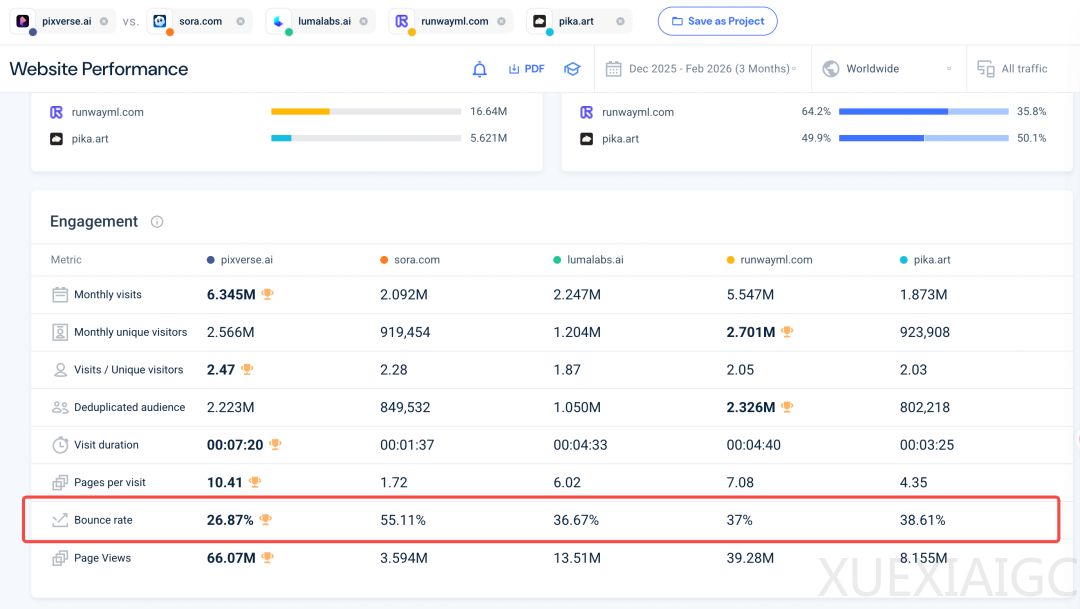
支持15秒连续生成,且响应速度较快。
虽在人声多样性上尚有改进空间,但其训练成本仅为同行约十分之一,用户留存率居行业首位,已形成明确商业闭环路径。
融资3亿美元佐证其技术路径获得资本认可,被视为有望成长为视频生成赛道领军者。
业内普遍认为,视频模型是构建世界模型的关键入口,因其能同时承载空间、时间与物理关系;相较于文本或语音,视频更能支撑AI对现实世界的深度理解与交互演进。
该进展预示视频生成将深度渗透影视制作、广告短剧、动漫等领域,重构数字内容创作范式。
原文和模型
【原文链接】 阅读原文 [ 2507字 | 11分钟 ]
【原文作者】 AI产品阿颖
【摘要模型】 qwen3-vl-flash-2026-01-22
【摘要评分】 ★☆☆☆☆

© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章

暂无评论...

