文章摘要
【关 键 词】 AI模型、参数优化、数据训练、推理能力、开源技术
一款仅有30亿参数的小模型在数学和推理能力上超越了320亿参数的大模型,这一突破性成果由BOSS直聘Nanbeige大语言模型实验室通过其开源的Nanbeige4-3B模型实现。该模型通过23万亿Token的高质量数据训练重塑了小模型的潜能,远超常规3B级别模型几万亿Token的训练量。团队设计了一套混合数据过滤机制,包含基于标签的评分和基于检索的召回两个核心维度,深入内容层面定义了超过60个维度,最终精选出20个关键维度进行人工标注。实验发现,内容相关的标签比格式标签更能预测数据质量,精细打分比简单的二分类更准确,配合检索数据库剔除了数十万亿低质Token,保留了23T高质量数据作为模型的知识底座。
训练调度方面,传统的WSD调度器被革新为FG-WSD(细粒度预热-稳定-衰减)调度器,其核心在于渐进式优化。在稳定训练阶段,高质量数据的比例逐步提升,确保模型持续获得新信息刺激。实验数据显示,使用FG-WSD的模型在GSM8k和MMLU上的得分显著提升。调度器还采用ABF方法将上下文长度扩展到64K,使模型能够完整消化长文本。
后训练阶段,团队打破了高质量微调数据只需少量的行业迷思,清洗并构建了约3000万条高质量问答样本,涵盖数学、代码和学科推理。所有训练数据的上下文长度被拉到32K,为模型注入强大的推理先验。全面SFT阶段进一步引入复杂任务,设计了一套解决方案精炼与CoT重构的联合机制,通过多维评估清单和教师模型生成候选答案,确保训练数据既有正确终点又有清晰路径。
Nanbeige4-3B采用DPD(双重偏好蒸馏)方法,让学生模型学习教师模型的概率分布并纠正错误。强化学习阶段划分为STEM、代码和人类偏好三个阶段,避免混合训练导致的领域能力互斥。STEM阶段引入工具增强的验证器,代码阶段采用合成测试函数策略,人类偏好对齐阶段训练成对奖励模型,确保模型表现符合人类直觉。
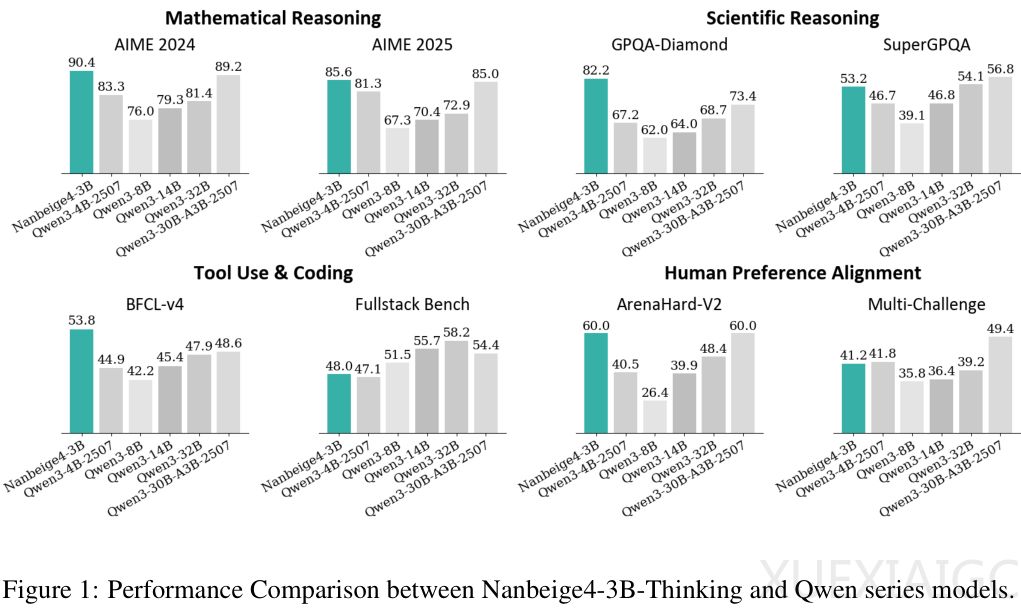
性能方面,Nanbeige4-3B在与Qwen系列模型的对比中展现出越级打击能力。在AIME 2024基准测试中,其90.4分远超同级别甚至参数量十倍于己的模型。科学推理、代码和工具使用以及人类偏好对齐方面同样表现优异。这一成果重新定义了3B参数量级的意义,证明通过极致的数据工程和算法设计,小模型可媲美甚至超越大模型,为受限于计算资源的开发者提供了优质选择。
原文和模型
【原文链接】 阅读原文 [ 2565字 | 11分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章


