CAIR开源发布超声基座大模型EchoCare“聆音”,10余项医学任务性能登顶
文章摘要
【关 键 词】 人工智能、超声影像、医疗技术、开源模型、临床验证
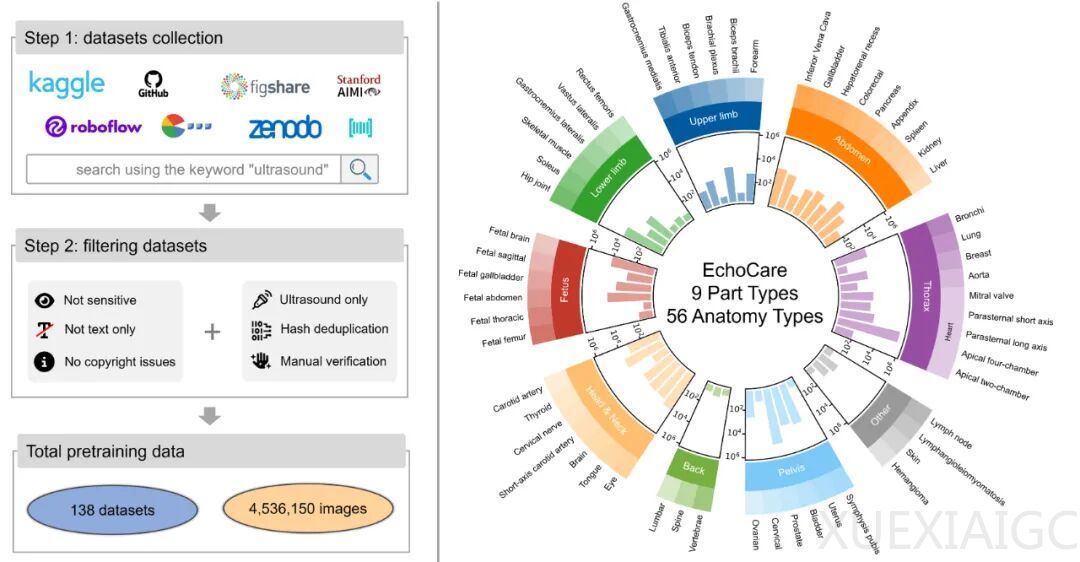
中国科学院香港创新研究院人工智能与机器人创新中心(CAIR)正式开源发布EchoCare“聆音”超声基座大模型,该模型基于超过450万张涵盖50多个人体器官的超声影像数据集训练而成。在器官识别、分割、病灶分类等10余项任务中性能全面超越现有最优模型,临床回溯性验证显示平均性能提升3%~5%。其首创的结构化对比自监督学习框架,有效解决了传统超声AI对大规模标注数据的依赖、长尾分布处理困难等核心难题。
超声诊断虽占据医学影像检查总量的70%,但AI应用长期受制于图像多变性和算法局限性。设备差异和操作变量导致传统模型面临“碎片化开发”困境,现有方案普遍存在数据量不足(低于100万张)、架构未针对超声特性优化等短板。“聆音”以数据高效性、场景适应性和临床实用性为标准,通过三大技术突破重构研发范式:构建全球规模最大的EchoAtlas数据集,涵盖五大洲20国、130种设备的450万张图像;创新设计层级化双分支架构,图像编码器增强抗噪声能力,双解码器模拟医师诊断思维;采用两阶段训练策略,自监督预训练阶段通过树形标签结构实现语义关系编码,微调阶段仅需40%-60%标注数据即可适配新任务。
临床验证显示,“聆音”在7大类任务中表现卓越:甲状腺结节分割DSC达83.17%,血管分割mDSC指标82.24%,均领先现有模型2%-3%;甲状腺恶性结节鉴别AUC 86.48%,<1cm结节检出率提升11.3%,可减少30%不必要活检;胎儿心胸比测量误差<5%的病例占89.2%,左心室射血分数计算MAE比USFM低19%。模型还展现出强大的基层适配性,低质量图像增强指标NIQE和BRISQUE优于专业增强模型,单图分析耗时<0.5秒满足实时需求。
该模型的技术价值在于建立了“数据-架构-验证”的完整研发体系,公开的EchoAtlas数据集和模型代码将推动行业协同创新。未来需加强多模态融合和动态序列处理能力,计划通过10家医院多中心试验深化临床落地。随着技术演进,超声AI将从专用工具发展为覆盖诊断全流程的决策伙伴,其开源策略有望加速医疗资源普惠化进程,为精准医疗提供核心支撑。
原文和模型
【原文链接】 阅读原文 [ 2897字 | 12分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★☆


相关文章


