DiT在数学和形式上是错的?谢赛宁回应:不要在脑子里做科学
文章摘要
【关 键 词】 DiT模型、TREAD方法、架构缺陷、技术质疑、算法迭代
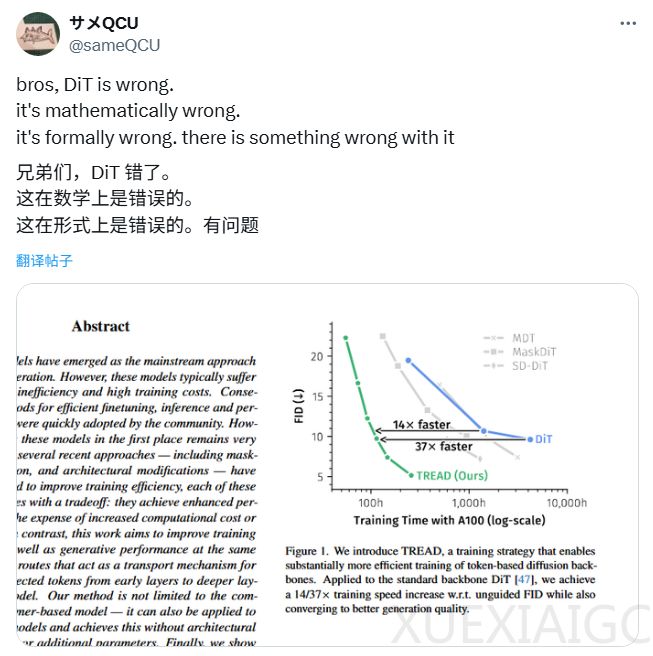
近期,一篇在 X 上的帖子引发了关于 DiT 模型的讨论。博主称 DiT 存在架构缺陷,并附上论文截图,图中展示了 TREAD 方法在提升基于 token 的扩散模型骨干网络训练效率上的优势,当应用于标准 DiT 骨干网络时,实现了 14/37 倍的训练速度提升,且收敛到更好的生成质量。博主认为该图暗示 DiT 的 FID 过早稳定,可能存在「隐性架构缺陷」,导致其无法继续从数据中学习。
今年 1 月发表(3 月更新 v2)的论文介绍了 TREAD 新方法,它通过创新的「令牌路由」机制,在不改变模型架构的情况下,提升了训练效率和生成图像质量,超越了 DiT 模型。TREAD 在训练中使用「部分令牌集」与「完整令牌集」,通过预定义路由保存信息并引入深层,跳过部分计算以降低成本,仅用于训练阶段,推理时采用标准设置,比 MaskDiT 等方法更高效。
博主进一步批判 DiT,指出论文揭示其设计缺陷,如将模型部分计算单元替换为「恒等函数」,模型最终评估分数反而提高。还指出 DiT 两个「可疑」设计:一是整个架构使用「后层归一化」处理扩散过程,该技术已知不太稳定;二是 adaLN – zero 在处理关键「指导信息」时用简单 MLP 网络,限制了模型表达能力。
DiT 由纽约大学谢赛宁于 2022 年提出,是扩散模式与 Transformer 首次结合,其核心是用 Transformer 代替传统卷积神经网络作为扩散模型主干网络,成为 Sora 和 Stable Diffusion 3 的基础架构。面对此次质疑,谢赛宁发推回应,虽对原帖有情绪,但也承认研究者梦想是发现架构问题。他从技术角度反驳部分问题,也说明 DiT 架构存在硬伤,如 tread 更接近 stochastic depth,Lightning DiT 是稳健升级版,无证据表明 post – norm 有负面影响,过去一年最大改进在内部表示学习,应优先采用随机插值 / 流匹配等,真正「硬伤」是 DiT 里的 sd – vae 臃肿低效且非端到端。评论网友对技术细节感兴趣,谢赛宁也进行了回复。算法迭代进步常伴随着对现有算法的质疑,而 DiT 仍有重要地位。
原文和模型
【原文链接】 阅读原文 [ 1822字 | 8分钟 ]
【原文作者】 机器之心
【摘要模型】 doubao-1-5-pro-32k-250115
【摘要评分】 ★★★☆☆


相关文章


