LLM强化学习不稳定之谜,被Qwen团队从「一阶近似」视角解开
文章摘要
【关 键 词】 强化学习、大语言模型、序列优化、训练稳定性、专家路由
强化学习(RL)已成为提升大语言模型(LLM)复杂推理能力的关键技术范式,但其训练稳定性问题亟待解决。当前主流RL算法存在序列级奖励与token级优化的不匹配现象,尤其在混合专家(MoE)模型中,动态路由机制可能破坏token级重要性采样的有效性。阿里千问团队提出了一种全新RL公式化方法,核心在于通过token级替代目标一阶近似序列级奖励期望,该近似需满足训练-推理数值差异和策略偏差足够小的条件。
研究从理论层面解释了多种RL稳定训练技巧的有效性。例如,重要性采样权重天然存在于token级替代目标中;剪切机制通过限制策略变化幅度抑制策略陈旧;MoE模型中的路由重放方法通过固定专家路由减少训练差异与策略偏差。实验采用30B参数的MoE模型,耗费数十万GPU小时验证理论,发现带重要性采样的基本策略梯度方法在on-policy训练中稳定性最高。当引入off-policy更新加速收敛时,必须同时使用剪切和路由重放来缓解策略陈旧导致的不稳定性。
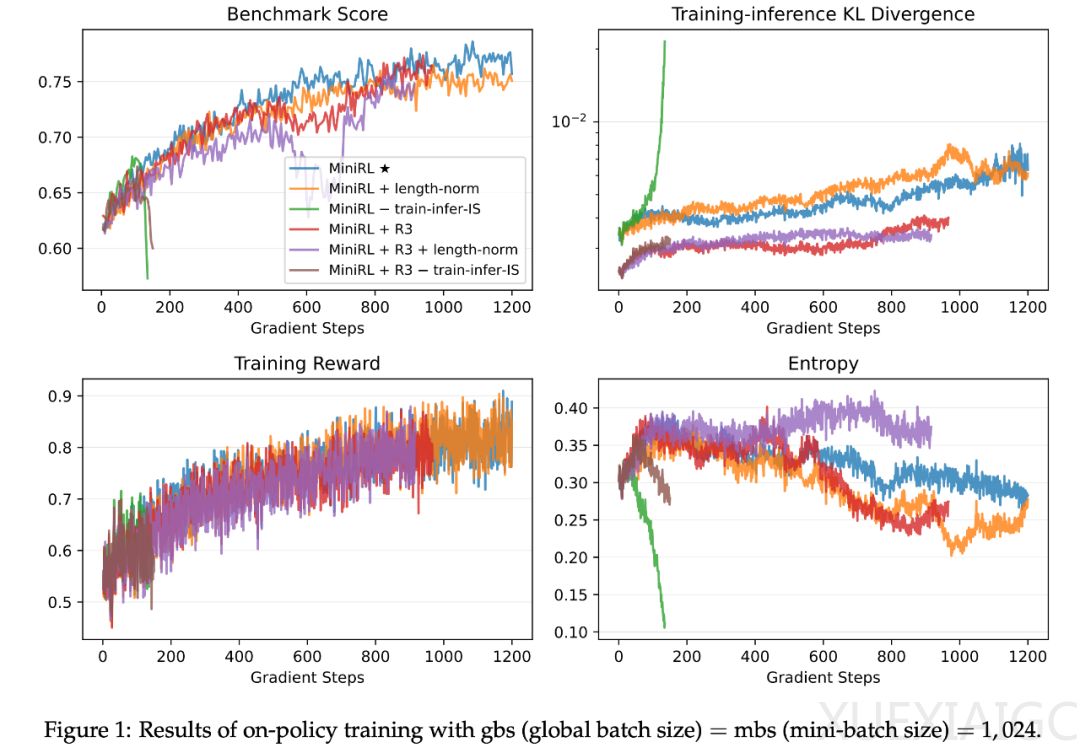
研究揭示了冷启动差异的临时性特征:随着RL训练持续,不同初始化方式的模型性能最终趋同,表明未来研究应更聚焦RL方法本身而非冷启动细节。在数学推理任务实验中,团队构建了包含4096道题目的提示集,并在竞赛级基准测试中验证方法有效性。结果显示,移除重要性采样校正会导致训练崩溃,证明其为一阶近似的必要组成部分;而长度归一化会破坏近似效果,导致性能下降。
对于MoE模型,路由重放技术展现出双重优势:既能通过固定路由专家减轻训练-推理差异,又能降低策略陈旧影响。实验数据表明,在off-policy场景下,路由重放与剪切机制的协同作用对维持稳定性至关重要。该研究不仅为LLM的RL训练提供了理论框架,还通过大规模实验验证了稳定训练实践方案,证明优化序列级奖励的token级近似方法在满足特定条件时具有理论合理性和实践可行性。
原文和模型
【原文链接】 阅读原文 [ 2562字 | 11分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★☆


相关文章


