LeCun在Meta还有论文:JEPA物理规划的「终极指南」
文章摘要
长期以来,AI领域致力于开发能像人类一样直观理解物理世界并在陌生任务中灵活应对的智能体。传统强化学习方法依赖大量试错和样本,在奖励信号稀疏的现实环境中效率低下。为解决这一问题,研究者提出「世界模型」概念,即让智能体通过内部物理模拟器预测未来状态进行演练。然而,现有生成式模型虽能生成精美像素画面,却难以高效提取物理规划所需的抽象信息,这引出了本研究的核心——JEPA-WM(联合嵌入预测世界模型)。
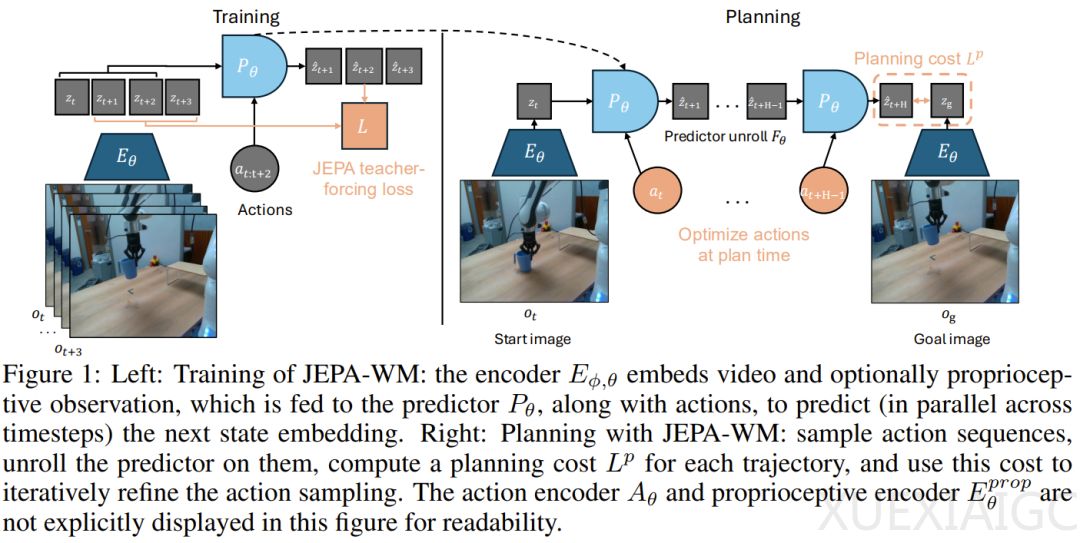
JEPA-WM基于Yann LeCun的JEPA架构,专注于抽象表征空间的预测而非像素级重建。该模型通过层次化架构实现物理规划:视觉编码器采用预训练ViT权重提取空间特征;本体感受编码器捕捉机器人关节角度和位姿;动作编码器将控制指令转化为特征向量;预测器则在因果掩码保护下并行预测未来状态嵌入。训练中引入多步展开损失和截断反向传播,确保模型能基于自身预测递归生成后续状态。动作干预方案对比显示,自适应层归一化(AdaLN)能有效防止动作信号在深层网络中衰减,成为最优选择。
规划过程被建模为动作空间优化问题。智能体通过内部模型试运行候选路径,以预测终点与目标嵌入的距离为评价标准,通过迭代收敛至最优动作。实验覆盖Metaworld、Push-T、PointMaze及真实机械臂数据集DROID,结果显示:在平滑成本曲线的任务中,梯度优化器表现优异;而在复杂导航任务中,基于采样的交叉熵方法(CEM)因探索能力更强而胜出。新引入的Nevergrad规划器则展现出跨任务迁移优势。
控制变量实验揭示了影响物理规划的关键因素:本体感受信息显著提升规划精度;DINO系列编码器凭借细粒度分割能力优于视频编码器;AdaLN动作调节技术兼具性能与效率;2-5帧的上下文长度是预测速度信息的最佳窗口;模型规模需与任务复杂度匹配——简单环境中小模型更高效,复杂现实场景则需大容量架构。多步损失(2-6步)的引入进一步提升了预测器的长时稳定性。
研究最终提出分层配置方案:模拟器环境采用ViT-S与AdaLN组合,真实复杂场景则使用DINOv3 ViT-L配以12层深度预测器。该方案在跨任务测试中全面超越DINO-WM和V-JEPA-2-AC等基线模型,为机器人实现更理性的物理规划提供了可扩展的技术路径。
原文和模型
【原文链接】 阅读原文 [ 2239字 | 9分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章


