文章摘要
【关 键 词】 音乐视频生成、级联架构、数字人技术、多模态模型、摄像机控制
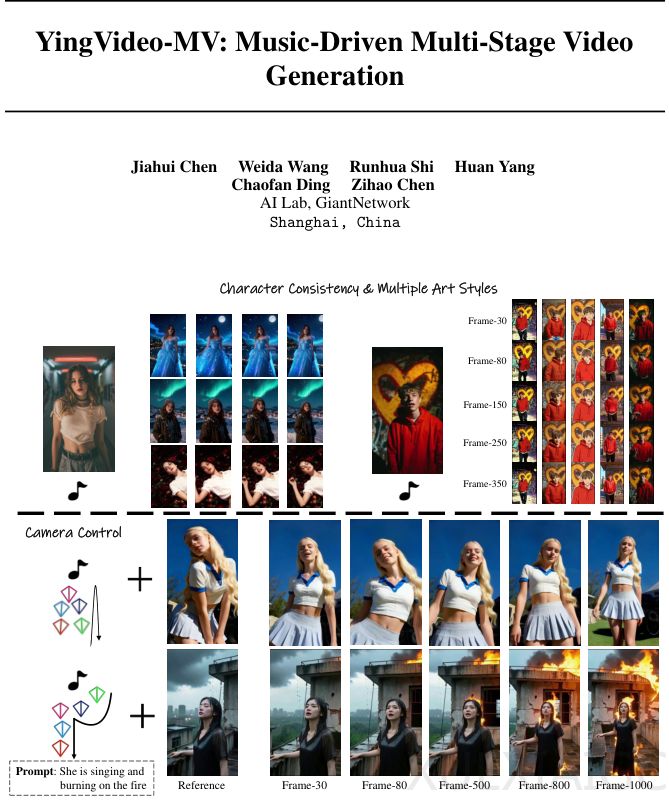
上海巨人网络AI实验室提出的YingVideo-MV框架通过创新的级联架构,将音乐语义分析、导演级镜头规划与时间感知视频生成相结合,显著提升了音乐视频生成的质量。该技术突破了传统音频驱动视频生成中运镜单一和长序列画面崩坏的限制,实现了精准口型同步、自然肢体动作与丰富运镜的高质量输出。数字人技术在音乐视频、Vlog和广告领域的应用面临的核心挑战在于如何让虚拟形象呈现具有感染力的表演,而非简单的对口型。现有模型通常难以处理复杂运镜、场景调度及长时间连续表演,导致画面单调、动作僵硬或身份特征丢失。
YingVideo-MV采用”先想后做”的两阶段设计逻辑,将长视频生成拆解为可控的短片段生成与拼接任务。系统首先生成包含构图、节拍点和角色运动模式的镜头列表,再并行生成分镜头片段并进行时间对齐与视觉融合。框架的核心是MV导演模块,它像人类导演一样进行统筹规划,在用户设定的高级目标环境中运行。音乐源分割遵循按节拍剪辑原则,确保视觉节奏与听觉节奏同步,同时采用Qwen 2.5-Omni多模态大语言模型精准捕捉音乐情感属性,为画面生成提供高级控制信号。
摄像机轨迹设计模块结合电影摄影建模的最新进展,生成符合叙事逻辑的平滑运动路径。视频生成模块基于WAN 2.1框架,通过全时空注意力Transformer架构将导演意图转化为具体像素。系统采用Plücker嵌入表示摄像机位姿,并通过专门设计的摄像机适配器将几何信息有效注入扩散模型。为解决长序列生成的一致性问题,框架提出了时间感知动态窗口范围策略,通过动态调整剪辑位置和长度确保画面连贯性。
在训练优化方面,系统引入直接偏好优化(DPO)提升视频美学质量。通过加权聚合唇形同步置信度、手部质量奖励分数和VideoReward分数,模型能够区分并优先生成符合人类审美的视频片段。实验数据表明,YingVideo-MV在视觉质量(FID 30.36)、时间一致性(FVD 193.68)和摄像机控制精度(平移误差4.85)等关键指标上均优于现有模型。用户盲测研究进一步验证了其在摄像机流畅性、口型同步和动作自然度方面的显著优势。
尽管在非人类实体和多角色互动场景仍存在局限,但YingVideo-MV通过将导演思维注入AI,为自动化音乐内容创作建立了工业标准与艺术表现力兼备的新范式。未来发展方向包括支持多角色交互式音乐视频,进一步提升对复杂几何结构和群体行为协调的处理能力。该技术的成功实践不仅推动了数字人应用的深度发展,也为多模态生成模型的工程化落地提供了重要参考。
原文和模型
【原文链接】 阅读原文 [ 3064字 | 13分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章


