文章摘要
【关 键 词】 AI大模型、Transformer、Mamba、状态空间模型、计算效率
Transformer架构在AI大模型领域占据主导地位,但其计算复杂度和能源需求随着序列长度呈二次方增长,引发了关于其可持续性的讨论。为解决这一问题,Mamba系列模型从状态空间模型(SSM)中汲取灵感,通过一系列创新实现了效率与性能的平衡。Mamba-3作为最新迭代版本,通过梯形离散化、复数状态空间和多输入多输出(MIMO)架构三大改进,显著提升了模型表现力和硬件利用率。
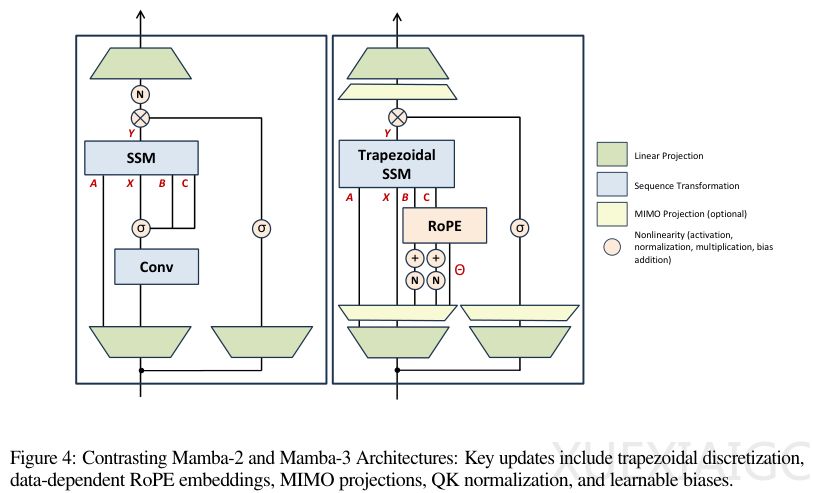
状态空间模型(SSM)最初用于预测连续系统变化,其核心是通过状态方程和输出方程描述系统动态。早期SSM存在训练效率低和长距离依赖问题,直到S4模型通过卷积实现高效训练和结构化矩阵解决记忆问题,为后续发展奠定基础。Mamba-3在此基础上引入梯形离散化方法,将误差从O(Δt²)降低到O(Δt³),显著提高了状态更新的精确度。这种方法不再需要短因果卷积组件,使架构更加简洁。
Mamba-3的另一项关键创新是引入复数定义SSM,通过旋转操作增强状态跟踪能力。这解决了实数特征值无法表示周期性状态转换的局限,使模型能够处理奇偶性判断等任务。这种改进被证明等效于在输入输出上应用数据相关的旋转位置嵌入(RoPE),以极小计算开销获得强大功能。在硬件效率方面,Mamba-3将状态更新从外积改为矩阵乘法,通过调整秩r提高算术强度,使解码过程从内存受限转向计算受限,充分发挥GPU性能。
实验数据显示,Mamba-3在不同参数规模下均优于Transformer、Gated DeltaNet和Mamba-2等基线模型。在推理效率方面,Mamba-3的MIMO版本在不增加状态大小的前提下,进一步推进了性能-效率的帕累托前沿。不过,固定状态大小的设计使其在需要精确检索的长文本任务上仍逊色于Transformer的KV缓存机制。消融研究证实了各项改进的有效性,特别是梯形离散化和RoPE对性能的显著提升。
Mamba-3代表了在计算效率和模型能力之间寻找最优解的探索,但其固定状态记忆机制仍是主要局限。未来可能的发展方向包括将Mamba-3与外部检索机制结合构建混合架构。这一系列创新不仅为AI模型提供了更高效的替代方案,也为解决大模型时代的算力和能源挑战开辟了新路径。
原文和模型
【原文链接】 阅读原文 [ 4180字 | 17分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章


