文章摘要
【关 键 词】 DINOv3、视觉模型、开源模型、性能出色、后处理优化
今天凌晨,全球社交、科技巨头Meta开源了最新视觉大模型DINOv3,其主要创新在于使用自我监督学习,无需标注数据,能大幅降低训练所需时间和算力资源。
– 模型参数与性能:DINOv3训练数据扩大至17亿张图像,参数达70亿,在图像分类、语义分割等10大类、60多个子集测试中表现出色,超越同类开、闭源模型,可助力医疗保健等多领域解锁更多用例。
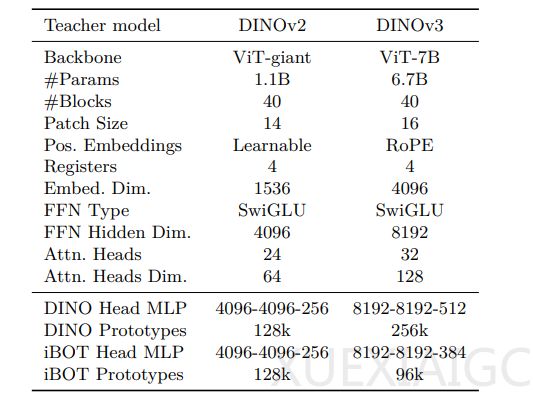
– 模型架构与优化技术:采用定制化的Vision Transformer架构,相比DINOv2,嵌入维度、注意力头数、前馈网络隐藏维度均有提升,还采用旋转位置嵌入和恒定超参数调度。为解决密集特征图退化问题,提出Gram锚定技术,强制学生模型的特征Gram矩阵与早期“教师模型”保持一致。训练阶段在100万次迭代后启动该优化,每10k次迭代更新教师模型,显著提升密集任务性能。
– 后处理优化策略:一是高分辨率适配,通过混合分辨率训练,使模型在高分辨率输入下保持特征稳定性,在1024×1024分辨率下语义分割性能提升15%。二是知识蒸馏,将70亿参数模型的知识蒸馏到更小变体中,形成模型家族,部分小模型性能接近大模型,或在资源受限场景下效率提升。三是文本对齐,冻结视觉主干网络,训练文本编码器与视觉特征对齐,支持零样本任务,在COCO图像 – 文本检索任务中表现良好。
– 多任务测试表现:在多个视觉任务测试中远超同类模型。语义分割任务中,在不同数据集上mIoU显著高于对比模型;深度估计任务中,RMSE低于对比模型;3D关键点匹配任务召回率领先;全局任务打破自监督模型性能瓶颈;视频与3D任务展现强大迁移能力;遥感与地理空间任务表现亮眼,如树冠高度估计误差降低,地理语义任务准确率和mIoU刷新纪录。
网友对DINOv3评价积极,认为它强大、通用且无需微调,希望集成到Llama大语言模型中,也期待它成为Meta的翻身之作。开源地址为https://huggingface.co/collections/facebook/dinov3 – 68924841bd6b561778e31009和https://github.com/facebookresearch/dinov3 。
原文和模型
【原文链接】 阅读原文 [ 1728字 | 7分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 doubao-1-5-pro-32k-250115
【摘要评分】 ★☆☆☆☆


相关文章


