Meta超级智能实验室又发论文,模型混一混,性能直接SOTA
文章摘要
【关 键 词】 大语言模型、模型融合、权重优化、性能提升、基准测试
大语言模型(LLM)的训练通常依赖大量算力和时间资源,而模型Souping(Model Souping)作为一种轻量级方法,通过对同一架构的多个模型进行权重平均,能够融合模型的互补能力,形成更强的新模型。传统的模型souping采用简单的均匀平均,而Meta和伦敦大学学院的研究者提出了基于类别专家的Soup(Soup Of Category Experts, SoCE),该方法利用基准测试的类别构成挑选最优模型候选,并通过非均匀加权平均最大化整体性能。
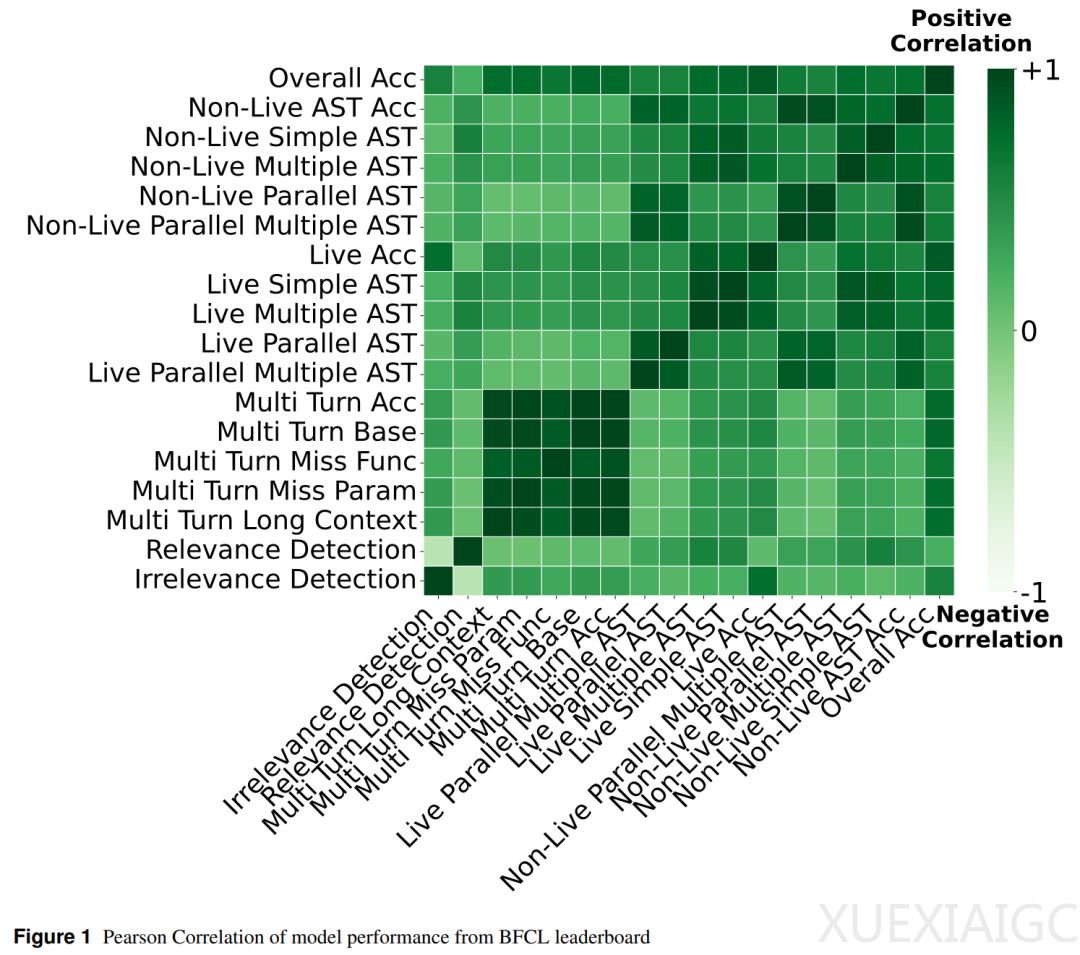
SoCE的核心洞见在于,不同基准类别之间的模型性能往往呈现弱相关性。例如,在Berkeley Function Calling Leaderboard(BFCL)中,多轮任务之间的相关性极高(0.96-0.98),而某些任务之间的相关性仅为0.07,表明它们是不同的能力维度。SoCE通过相关性分析、专家模型选择、权重优化和加权模型souping四个步骤,为每个弱相关类别簇挑选专家模型并优化加权方案。
实验结果显示,SoCE显著提升了模型效果与稳健性。在BFCL基准上,70B参数的SoCE模型达到80.68%的准确率,相比此前最佳单模型提升2.7%;8B参数的SoCE模型提升5.7%。权重优化阶段发现,70B模型的最优配置为xLAM-2-70b-fc-r(0.5)、CoALM-70B(0.2)和watt-tool-70B(0.3),而8B模型的最优配置为xLAM-2-8b-fc-r(0.7)、ToolACE-2-8B(0.2)和watt-tool-8B(0.1)。
消融研究证实,SoCE的模型选择步骤对性能提升至关重要。在多语言数学推理(MGSM)等基准上,SoCE的表现均优于候选模型和均匀平均souping。此外,模型souping后类别间的线性相关性显著提升,且在37项实验中的35项中,超过20个类别的指标得分更高,所有类别的净性能增益均为正。这表明SoCE能够有效结合不同模型的专长,实现稳定且全面的性能改进。
原文和模型
【原文链接】 阅读原文 [ 1513字 | 7分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★☆☆☆☆


相关文章


