文章摘要
【关 键 词】 人工智能、大语言模型、自我学习、搜索智能体、零数据训练
Meta超级智能实验室与伊利诺伊大学联合开发的Dr. Zero框架,通过零数据自我进化机制实现了搜索智能体的突破性进展。该框架完全摒弃人类标注数据,仅依赖搜索引擎和自我博弈训练大语言模型,其性能已超越传统监督学习方法。在人工智能面临高质量数据枯竭的背景下,这种让模型通过实践自主学习的路径成为突破数据瓶颈的关键。
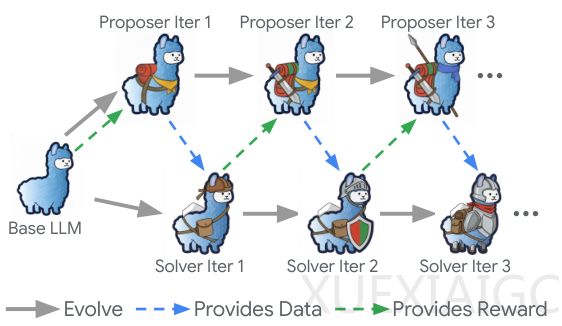
Dr. Zero的核心创新在于构建了提问者与解答者的共生博弈系统。同一基座模型分化为两个角色:提问者负责生成问题,解答者通过搜索引擎寻找答案。为避免陷入低水平循环,系统设计了多轮工具调用流程和动态奖励机制。提问者需先验证信息可获取性再生成问题,而奖励机制则根据解答者的”跳一跳够得着”状态进行调节,这种设计迫使系统自动构建出由浅入深的训练课程,最终涌现出处理多跳问题的复杂能力。
针对训练效率问题,研究团队提出跳数分组相对策略优化(HRPO)方法。该方法按问题所需推理步骤数分组,以组内平均表现作为基准,既降低计算成本又保持训练稳定性。实验数据显示,基于Qwen2.5-3B模型的Dr. Zero在Natural Questions等单跳任务上准确率达0.397,显著超过监督学习的0.323。当模型规模扩展至7B时,在2WikiMQA等多跳任务中实现反超,验证了框架的扩展潜力。
跨基准测试表明,Dr. Zero在开放域问答任务中全面碾压现有无数据方法,平均得分比次优方案高出7个百分点。训练动态分析揭示,模型在初期迭代进步显著,后期则进入微调阶段。值得注意的是,7B模型存在过迭代导致性能波动的现象,这为自主进化过程的稳定性研究提供了新方向。
这项研究证实,通过合理的工具配置和激励机制,AI系统完全可能实现不依赖人类数据的自主进化。该成果不仅为数据稀缺领域的智能体开发开辟了新路径,更重新定义了机器智能的学习范式——未来AI或许只需在类似Dr. Zero的竞技场中,就能自主掌握探索世界的复杂能力。
原文和模型
【原文链接】 阅读原文 [ 2972字 | 12分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章


