文章摘要
【关 键 词】 AI技术、Transformer模型、机器学习、自然语言处理、模型优化
Meta FAIR部门研究员François Fleuret近期发表的论文《The Free Transformer》提出了一种创新性的解码器Transformer扩展方案。这项技术的核心突破在于让模型在生成每个token前,能够通过潜变量Z形成内部决策框架,实现”先规划后执行”的生成模式,显著提升了编程、数学推理等复杂任务的性能表现。
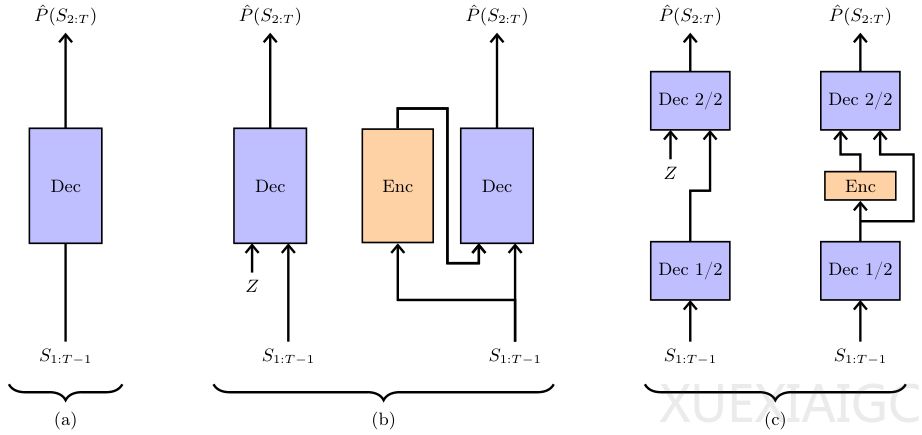
传统解码器Transformer存在明显的惯性困境。模型只能基于已生成内容逐字预测,导致全局意图必须通过零散词语被动推断,这种机制不仅低效,还容易因早期偏差引发后续生成失控。以电影评论生成为例,标准模型无法预先确定情感倾向,而是随着词汇累积逐渐显现态度,这种被动推理方式在面对非常规数据时尤为脆弱。
Free Transformer通过引入变分自编码器(VAE)框架解决了这一根本问题。模型首先采样随机变量Z来编码全局属性(如评论情感),再基于Z指导完整序列生成。关键技术在于:1) 采用非因果Transformer块构建编码器,实现全序列信息捕捉;2) 通过KL散度惩罚控制Z的信息量,防止编码器过度压缩数据。实验数据显示,这种改造仅增加约3%的计算开销,却带来显著性能提升。
合成数据集实验验证了潜变量的有效性。通过调节KL阈值,模型依次掌握了目标位置编码(κ=0.1)、噪声模式识别(κ=0.5)等关键能力。当阈值过高时会出现信息过载现象,证明Z的信息量需要精确控制。在HumanEval+、MBPP等基准测试中,8B规模的Free Transformer在代码生成和数学推理任务上表现突出,特别是在每个token引入0.5比特信息时达到最优。
这项研究标志着对Transformer核心机制的重要革新。与思维链等显式推理方法不同,Free Transformer在潜在空间实现隐式规划,为模型提供了更接近人类”先构思后表达”的生成逻辑。未来研究方向包括优化训练稳定性、探索不同Z嵌入形式,以及验证该架构在超大规模模型中的适用性。这项工作证明,即使对成熟架构进行微小改造,仍可能引发显著的性能突破。
原文和模型
【原文链接】 阅读原文 [ 2285字 | 10分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章


