文章摘要
【关 键 词】 高带宽内存、AI算力、3D堆叠、内存技术、未来趋势
高带宽内存(HBM)作为AI算力发展的关键支撑技术,正在经历从HBM3到HBM8的快速迭代升级。韩国KAIST大学TERALAB实验室发布的《HBM Roadmap Ver 1.7》揭示了未来15年HBM技术的发展路径,其核心目标是通过持续提升带宽、降低延迟、优化能效,彻底解决AI计算中的“内存墙”瓶颈。报告显示,HBM的带宽将从HBM3的819GB/s跃升至HBM8的64TB/s,增幅达78倍,这一进化背后依赖三大关键技术:硅通孔(TSV)、混合键合(Cu-Cu Bonding)和AI辅助设计。
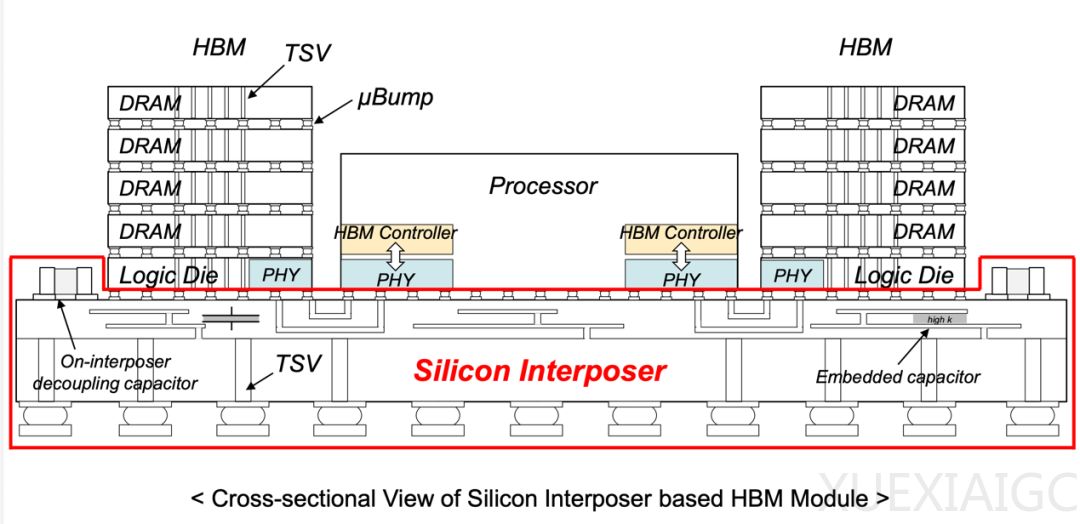
HBM的核心价值在于重构了内存与计算单元的关系。传统DDR5内存受限于平面布局和有限带宽,导致GPU时常处于“数据饥饿”状态;而HBM通过3D堆叠架构,将存储单元垂直堆叠于计算单元旁,数据通道从“平面公路”升级为“立体空运”。以HBM3为例,其819GB/s带宽相当于每秒传输205部高清电影,延迟低至10纳秒,使GPT-3的训练时间从20天压缩至5天。这种突破源自“三明治式”堆叠设计:8-24层Core Die通过数万根TSV实现垂直互联,Base Die则演变为智能调度中心,HBM4甚至能绕过CPU直接管理LPDDR内存。
各代HBM的技术突破呈现清晰的场景化特征。2026年的HBM4通过定制化Base Die支持异构内存池,成本降低40%;2029年的HBM5集成近内存计算单元,使LLM推理速度提升1.5倍;2032年的HBM6采用四塔结构,AI客服请求吞吐量翻倍;2035年的HBM7融合高带宽闪存,实现17.6TB混合存储容量;2038年的HBM8通过全3D集成技术,将GPU与内存的互连延迟压缩至1纳秒以下。每一代升级都精准对应AI算力需求的演变——从中端服务器到AGI原型机。
功耗与散热技术的协同进化同样关键。从HBM4的直触液冷到HBM8的双面嵌入式冷却,散热效率提升5倍,保障了180W功率下的稳定运行。HBM5引入的去耦电容芯片将数据传输错误率控制在万亿分之一,HBM7的微型水道冷却技术实现78℃的精准温控。这些创新使HBM在性能倍增的同时,能效比持续优化——HBM4传输1TB数据的功耗仅为DDR5的50%。
TSV、混合键合和AI设计工具构成HBM的三大技术支柱。TSV作为“数据电梯”将层间传输路径缩短90%;铜-铜直接键合使I/O密度提升10倍;PDNFormer等AI模型将电源网络设计时间从2.8小时压缩至1毫秒。这些技术进步支撑起HBM8的夸张参数:24层堆叠、16384个I/O通道、64TB/s带宽,为AGI时代奠定存储基础。
未来十年,HBM将推动计算架构从“以计算为中心”转向“存算一体”。当HBM8实现GPU与内存的“立体共生”时,传统的内存层次结构将被彻底重构,AI算力发展可能迎来新的范式革命。这场始于数据带宽的技术进化,终将重塑整个计算生态。
原文和模型
【原文链接】 阅读原文 [ 7982字 | 32分钟 ]
【原文作者】 半导体行业观察
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章


