全球第二、国内第一!最强文本的文心5.0 Preview一手实测来了
文章摘要
【关 键 词】 百度文心、大模型、人工智能、基准测试、技术突破
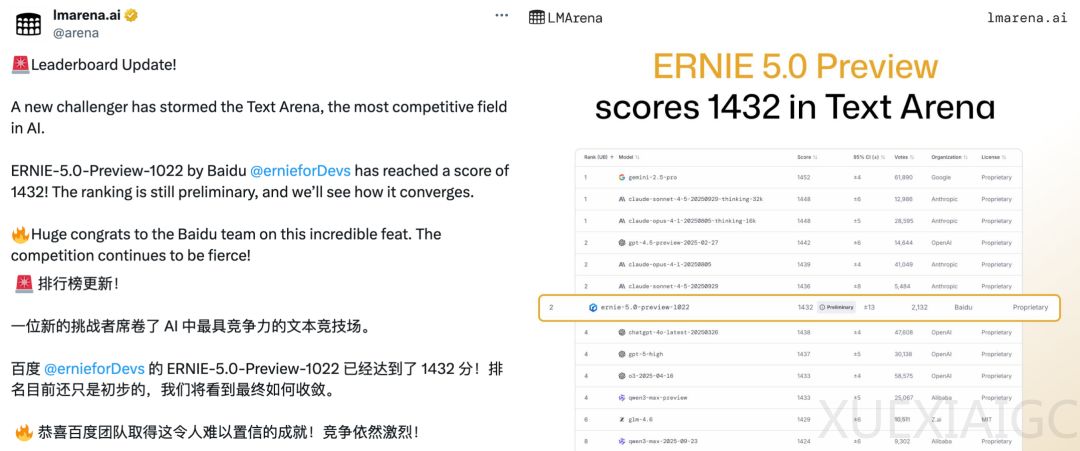
百度文心5.0 Preview模型在LMArena全球文本竞技场测试中取得1432分,与OpenAI的GPT-4.5 Preview及Anthropic的两款Claude模型并列全球第二,同时位列国内第一。这一成绩标志着百度文心系列模型在全球通用智能模型竞争格局中稳固了第一梯队的地位。LMArena作为由加州大学伯克利分校创建的开放评测平台,采用动态排名机制,通过真实用户对模型输出的偏好投票进行评估,其榜单结果被认为更贴近实际应用场景,具有较高含金量。
文心5.0 Preview在创意写作、复杂长问题理解和指令遵循三大核心能力测试中表现突出。创意写作任务排名第一,展现其在生成文章、营销文案等内容的速度与质量优势;复杂长问题理解排名第二,显示其处理学术问答、报告分析等高认知任务的能力;指令遵循排名第三,证明其在智能助理、代码生成等场景的适用性。这些成绩表明该模型在语义理解、逻辑推理与任务执行一致性上已形成领先优势。
通过横向对比测试发现,文心5.0 Preview在营销创意产出方面展现出超越同类产品的价值定位能力。与Claude Sonnet 4.5相比,其营销方案不仅准确捕捉”情绪价值”这一热门切口,更通过”灵感的合伙人”这一概念实现从工具到价值的跃升。在致创作者的公开信中,该模型直击AI时代关于原创性的核心焦虑,提出”AI越强大,人的创造力越珍贵”的独特视角。其短视频脚本创作的专业程度更是达到可直接执行的水平。
在复杂长问题理解测试中,文心5.0 Preview展现出超越简单信息检索的服务意识。当扮演客服角色时,该模型不仅准确回答问题,还能主动补充”和一个大苹果的重量差不多”等直观类比,显著提升用户体验。在条件推断和负面查询测试中,其回答风格简洁专业,准确解决用户担忧,展现了较高的场景适应能力。
指令遵循能力测试验证了文心5.0 Preview在复杂约束条件下的可靠表现。面对”禁用特定字词和标点”的多层反直觉指令时,该模型不仅能严格遵守规则,还能保持文本的可读性和信息密度。在要求同时满足禁用”的”字、逗号顿号,并分段编号的极端测试中,其生成的北京介绍依然条理清晰,且能精确执行”自我定量审计”的元指令要求。
百度全栈AI技术布局为文心模型的快速进化提供了底层支撑。从昆仑芯自研芯片、飞桨深度学习框架,到文心大模型和应用生态,百度构建了完整的”芯片-框架-模型-应用”技术闭环。飞桨框架与文心模型的联合优化,以及2333万开发者的生态支持,共同推动了模型性能的持续提升。这种全栈优势使百度成为全球少数具备AI技术完整架构的公司之一。
随着文心5.0正式版即将在百度世界2025大会亮相,中国AI技术体系正展现出从”追赶”向”引领”过渡的态势。此次测试成绩不仅验证了百度在通用人工智能领域的技术实力,也为AI技术在内容生产、企业智能体等场景的系统性赋能奠定了基础。国产大模型的持续突破,正在重塑全球AI竞争格局。
原文和模型
【原文链接】 阅读原文 [ 3532字 | 15分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章


