击败GPT、Gemini,复旦×创智孵化创业团队「模思智能」,语音模型上新了
文章摘要
【关 键 词】 语音识别、多说话人、长音频、端到端、性能突破
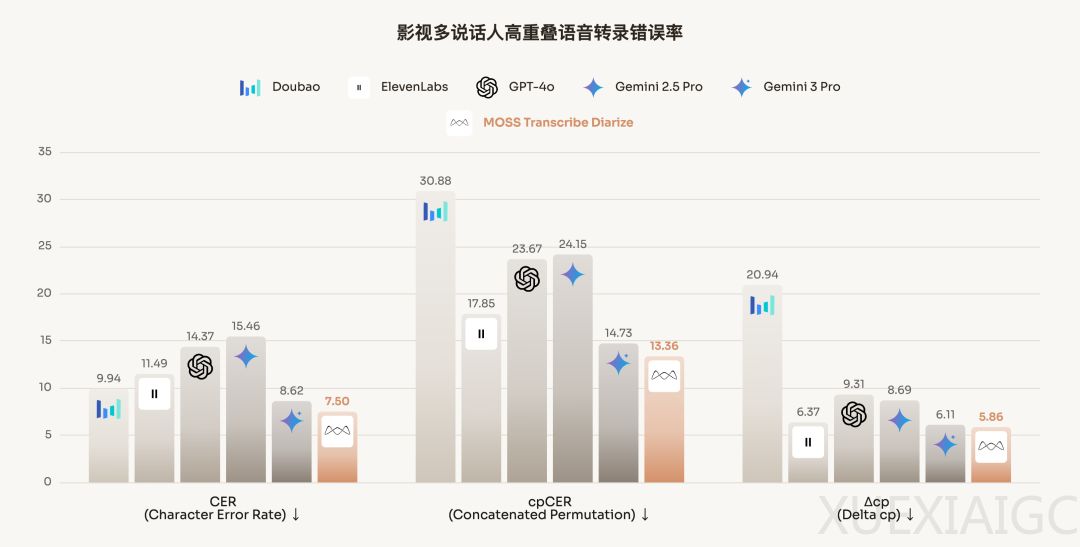
模思智能发布的多说话人自动语音识别模型MOSS-Transcribe-Diarize在语音识别与分析领域取得突破性进展。该模型由复旦邱锡鹏团队研发,能够同时完成语音转文字、说话人关联和时间戳标记三项任务,性能超越GPT-4o、Gemini等主流模型。其核心创新在于解决了多人说话场景下的转录痛点,包括混乱插话、频繁切话和重叠说话等复杂情况。
模型采用统一的端到端多模态架构,将声学表示投影到预训练文本LLM的特征空间,实现词汇内容、说话人归属和时间戳的联合建模。技术亮点包括支持128K长上下文窗口,可处理长达90分钟的音频;采用”虚实结合”的训练策略,结合真实对话和合成数据增强鲁棒性。在AISHELL-4、Podcast和Movies等基准测试中,模型在字错误率(CER)、最优排列字错误率(cpCER)和说话人分离性能(Δcp)三项指标上均达到业界最优。
相比传统方案,该模型克服了长上下文窗口受限、长时记忆脆弱和缺乏原生时间戳三大瓶颈。特别是在影视剧等复杂场景中,即使面对背景噪音、方言俚语和情感波动,仍能保持稳定的识别准确率。测试显示,GPT-4o和Gemini 3 Pro等商业模型在长音频处理和输出格式稳定性方面存在明显局限。
作为模思智能多模态技术路线的最新成果,该模型与其此前发布的MOSS-TTSD、MOSS-Speech形成技术闭环,覆盖语音生成、理解和交互全链条。团队战略聚焦”情境智能”,致力于通过规模化真实场景数据训练,实现自然连贯的多模态交互。目前模型已开放API接口,技术报告显示其端到端架构有效降低了传统级联方案的误差传播问题。
原文和模型
【原文链接】 阅读原文 [ 2643字 | 11分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★☆


相关文章


