文章摘要
【关 键 词】 AI安全、大模型、预训练、数据过滤、Token级
Claude价值观塑造者Neil Rathi与前OpenAI科学家Alec Radford共同发表的研究提出了一种革命性的AI安全方法。该方法主张在预训练阶段通过Token级数据过滤精准切除大模型的危险能力,而非传统的事后修补模式。研究表明,这种”精准外科手术”能以极低计算成本将特定危险能力削弱数千倍,同时保持模型的通用智能不受损害。
传统AI安全策略采用”先污染后治理”模式,依赖人类反馈强化学习或监督微调来限制模型行为,但这种方法已被证明极其脆弱。对抗性攻击和微调越狱总能绕过后天添加的护栏,诱导模型输出危险内容。新方法将过滤精度提升至Token级别,实现了去其糟粕取其精华的可能。研究团队以生物学和医学知识为测试案例,因为这两个领域知识图谱高度重叠,完美模拟了现实中移除危险知识同时保留有益知识的困境。
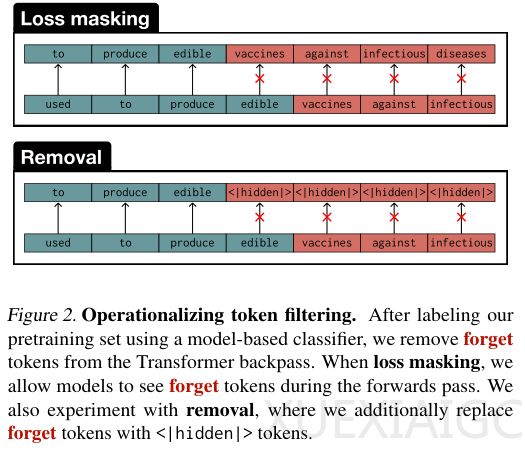
Token级过滤采用两种操作方式:损失屏蔽和直接移除。前者允许模型阅读但不学习敏感词,后者则用特殊占位符完全隐藏敏感内容。实验显示,相比于粗放的文档级过滤,Token级方法在同等程度削弱目标能力的情况下,对其他相关能力的保留效果显著更优。尤其值得注意的是,随着模型规模扩大,这种过滤方式的效果呈现指数级增长。对于18亿参数模型,攻击者恢复被过滤知识所需的计算量增加了7000倍。
在安全防御方面,Token级过滤展现出远超现有遗忘学习技术的抵抗力。面对对抗性微调攻击,传统方法极易失效,而经过Token过滤训练的模型则表现出类似从未学习过相关知识的状态。更令人意外的是,缺乏具体危险知识的模型反而展现出更优的拒绝能力,在处理非目标领域问题时也没有过度拒绝倾向。这表明模型建立了清晰的认知边界,能够区分已知与未知领域。
实施Token级过滤面临的主要工程挑战是大规模标签获取。研究团队开发了一套弱监督流水线解决方案,结合稀疏自编码器和小型双向语言模型,实现了高效自动化的Token标注。即使分类器存在一定误差,只要保持足够严格的过滤阈值,大模型仍能有效遗忘目标知识而不显著损害通用能力。这种方案不需要完美标注或昂贵人工审核,为万亿级别Token数据的精准过滤提供了可行路径。
这项研究颠覆了”模型必须知道危险才能避免危险”的传统认知,展示了有选择的无知可能成为AI安全的新范式。通过从源头阻断危险知识的摄入,未来的AI系统或许能在保持强大智能的同时,避免特定领域的危害风险。这种方法为构建更安全可靠的大语言模型提供了重要技术路线,可能深刻影响AI安全领域的发展方向。
原文和模型
【原文链接】 阅读原文 [ 3101字 | 13分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章


