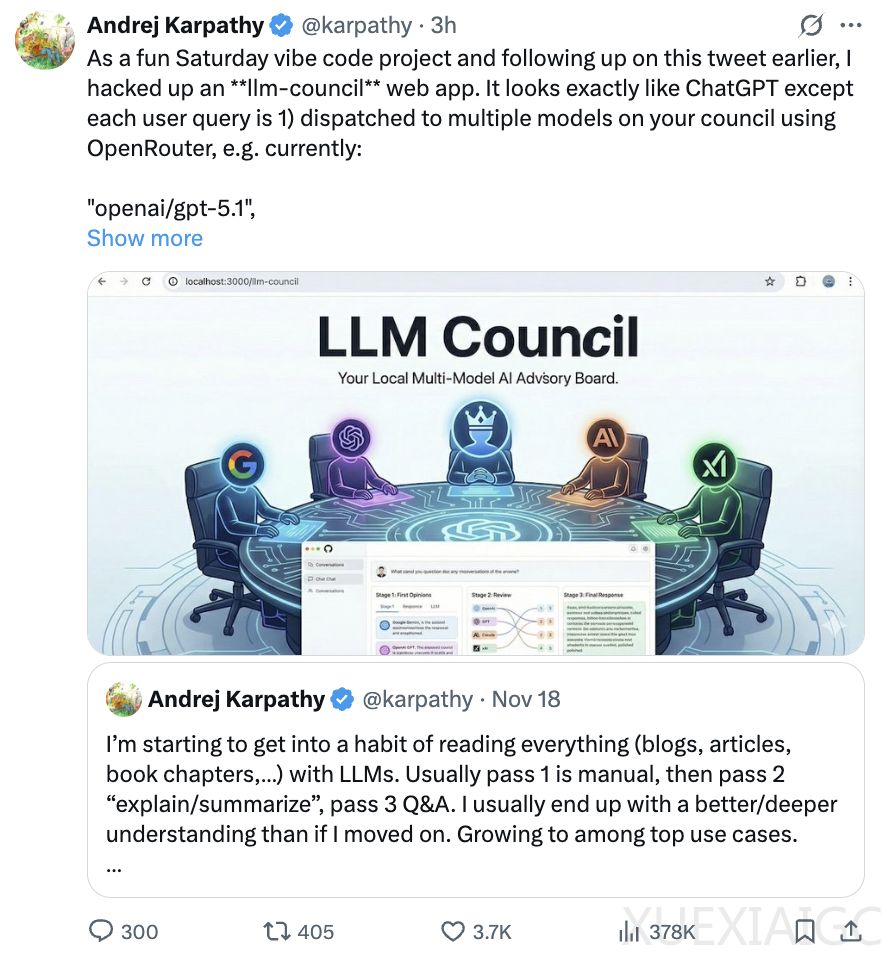
文章摘要
卡帕西最新发布的趣味编程项目“大模型议会”(LLM Council)引发关注。该项目通过web app形式,让多个大模型针对用户问题共同商议答案。系统利用OpenRouter调用GPT-5.1、Gemini 3 Pro Preview、Claude Sonnet 4.5和Grok-4等模型,采用三步流程:首先各模型独立回答问题,随后匿名互评,最后由主席模型汇总最终答案。这种设计允许用户直观对比不同模型的输出风格和互评逻辑。
技术实现上凸显创新性。模型互评阶段要求基于准确性和洞察力进行匿名打分,结果显示GPT-5.1被公认为表现最佳,Claude评分最低,Gemini和Grok-4居中。值得注意的是,卡帕西的主观评估与模型自评存在差异——他认为Gemini的回答更简洁高效,而GPT-5.1的内容虽丰富但结构松散。实验还发现,模型在互评时展现出客观性,能够坦然承认其他模型的优势。
该项目是卡帕西此前LLM分阶段阅读研究的延续,其GitHub版本已获1.8k Stars。核心价值在于探索多模型协作的可能性:通过三阶段阅读法(人工通读、模型解析、深度追问),将传统阅读转化为LLM中介的个性化知识传递。卡帕西推测,这种集成模式可能成为未来LLM产品的突破方向,特别是为自动评测基准(auto-benchmark)提供了新思路。开发者社区反响热烈,认为该方法既能对比模型能力差异,又揭示了模型自我评价机制的潜在研究价值。
原文和模型
【原文链接】 阅读原文 [ 914字 | 4分钟 ]
【原文作者】 量子位
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★☆☆☆☆

© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章

暂无评论...

