文章摘要
【关 键 词】 蚂蚁集团、大模型、开源、人工智能、FP8训练
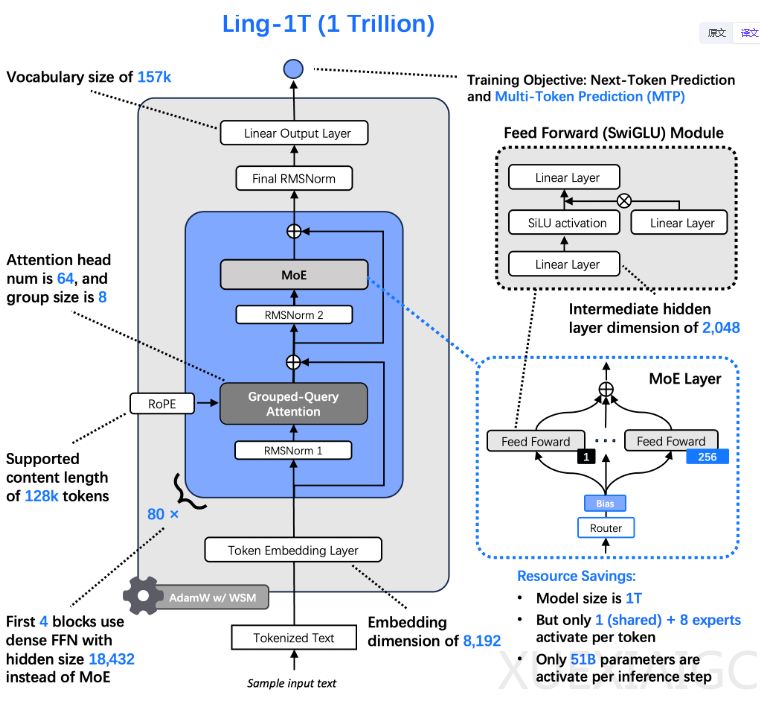
蚂蚁集团近期开源了其万亿参数旗舰大模型Ling-1T,这是全球已知采用FP8低精度模式训练的最大基座模型。该模型属于蚂蚁Ling 2.0家族,包含三个分工明确的系列:专注通用任务的Ling系列、擅长深度推理的Ring系列,以及处理多模态信息的Ming系列。Ling-1T采用混合专家(MoE)架构,总参数达1万亿,但每个token仅激活约500亿参数,通过1/32的专家激活比例显著降低运算成本。
训练万亿级模型面临巨大挑战,蚂蚁团队为此开发了“Ling缩放定律”,通过300多个模型实验总结出MoE架构中计算效率、专家激活比例与计算预算间的幂律关系。为解决训练稳定性问题,团队自研WSM学习率调度器,采用检查点合并技术实现自适应学习率调整,相比传统方法在数学、代码等硬核测试中提升数个百分点。模型架构还包含多项创新:MTP层增强组合推理能力,S型函数实现专家负载均衡,QK归一化确保大规模训练稳定性。
训练过程分为三阶段:预训练阶段消耗超过20万亿token数据,其中40%为推理密集型;中训练阶段引入思维链数据激活推理能力;后训练阶段采用演进式思维链技术持续优化。全程使用FP8混合精度,相比主流BF16实现15%的端到端加速,精度损失小于0.1%。
性能测试显示,Ling-1T在数学推理(AIME 25测试集70.42%准确率)、代码生成(ArtifactsBench开源模型第一)等任务表现突出。其扩展了推理准确性与长度间的帕累托前沿,在工具调用测试(BFCL V3)中仅经轻度微调即达70%准确率。社区测试验证了其在物理模拟、宇宙演化等复杂场景的应用潜力。不过模型目前存在处理超长上下文(>128K)时成本较高的问题,团队正研发混合注意力架构进行优化。
作为当前最佳开源非思考模型,Ling-1T在保持高效通用处理的同时,其推理能力已可媲美闭源API。蚂蚁同步公开了HuggingFace、ModelScope等平台的开源地址及国内体验通道,推动大模型技术生态发展。
原文和模型
【原文链接】 阅读原文 [ 1730字 | 7分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★☆


相关文章


