文章摘要
【关 键 词】 AI模型、数学竞赛、算法设计、训练成本、开源技术
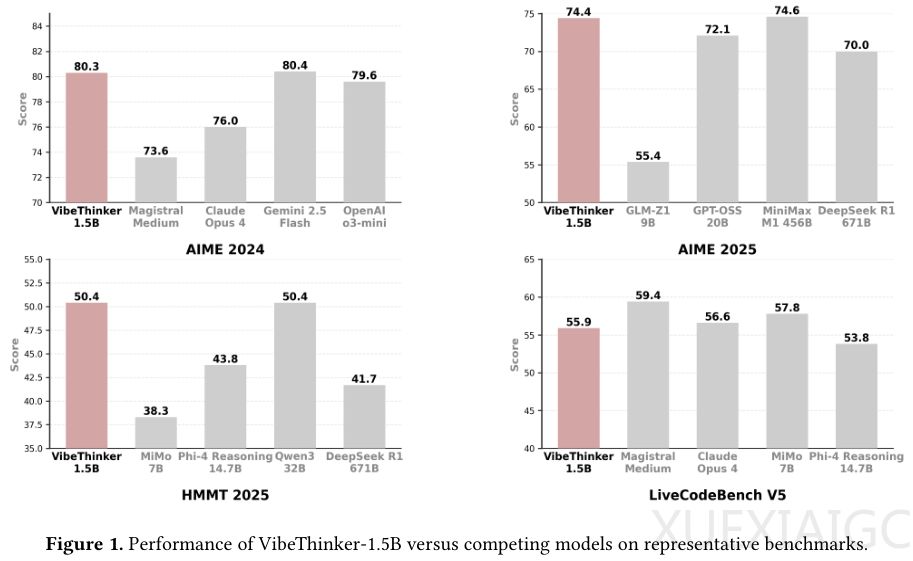
新浪微博近期开源的VibeThinker-1.5B模型以15亿参数、不足8000美元的训练成本,在多项顶级数学竞赛基准上击败了参数量达6710亿的DeepSeek-R1等巨型模型。这一突破性成果挑战了”模型性能与参数规模正相关”的行业共识,其成功源于创新的”频谱到信号原则”(SSP)训练哲学,该原则通过解耦监督微调(SFT)和强化学习(RL)阶段的目标,实现了思维广度与精度的协同优化。
SSP原则颠覆了传统训练范式,将SFT阶段重新定义为”频谱阶段”。该阶段不再追求单次回答准确率(Pass@1),而是鼓励模型生成多样化解题方案(Pass@K)。团队采用领域感知多样性探测技术,针对数学各子领域训练出专项”多样性专家模型”,再通过参数融合形成全能SFT模型。这种设计使模型在代数、几何等细分领域均能保持高水平的思维发散能力,为后续优化提供了丰富的解决方案储备。
RL阶段作为”信号阶段”,采用最大熵引导策略优化(MGPO)框架动态识别模型学习甜点区。通过熵偏差正则化加权,模型能优先处理那些处于50%正确率的”模糊地带”问题,显著提升训练效率。这种机制确保模型能从SFT提供的广阔频谱中精准锁定最优解,实现从思维多样性到答案准确性的高效转化。
在MATH-500、HMMT2025等权威测试中,VibeThinker-1.5B展现出惊人性能:AIME25分数较基础模型提升17倍,HMMT25从0.6跃升至50.4,编程基准LiveCodeBench V5更是实现从0到55.9的突破。尤其值得注意的是,其数学表现超越GPT-4.1等万亿参数通用模型,验证了专用推理模型的效能优势。虽然在小参数模型固有的知识广度限制下,GPQA等百科测试表现仍有差距,但该模型在逻辑推理领域的专注优化成效显著。
仅3900个H800 GPU小时、不足8000美元的训练投入,却达到传统方法需30-50万美元才能实现的性能水平。这种成本效益比不仅大幅降低AI研发门槛,更使模型能部署于手机等边缘设备。严格的数据去污染措施和时间线验证(测试题晚于基础模型发布)有力证实了其能力提升源于算法创新而非数据泄露。这项成果为AI发展提供了新范式:在特定认知领域,精妙的算法设计可能比单纯的算力堆砌更具突破潜力。
原文和模型
【原文链接】 阅读原文 [ 3667字 | 15分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章


