攻克大模型训推差异难题,蚂蚁开源新一代推理模型Ring-flash-2.0
文章摘要
【关 键 词】 Ring-flash、棒冰算法、长思考难题、性能成本、开源礼包
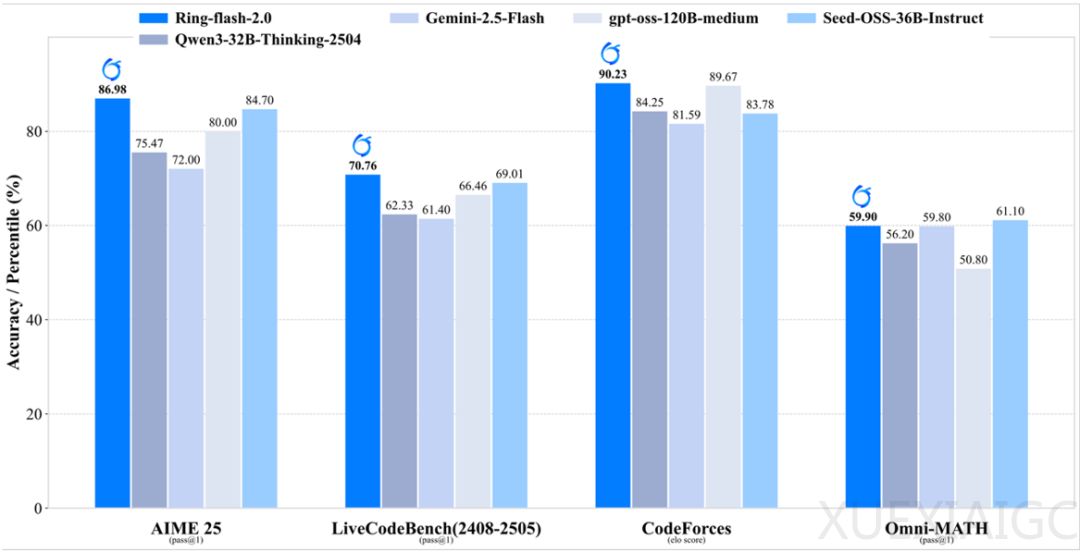
蚂蚁百灵大模型团队于 9 月 19 日发布开源礼包 Ring-flash-2.0,其 100B 总参、6.1B 激活,数学 AIME25 拿下 86.98 分,CodeForces elo 分数 90.23,128K 上下文实测 200+token/s。该模型通过独创棒冰(icepop)算法和长周期的 RL 训练,在多项推理榜单上取得显著突破,性能达 40B 以内 dense 模型的 SOTA 水平,甚至可与参数量更大的 MoE 模型媲美。
在解决 MoE 长思考难题方面,2025 年业内存在长思维链场景下 MoE 模型 RL 训练奖励崩溃问题,而 Ring-flash-2.0 的棒冰(icepop)算法实现双向截断 + 掩码修正,“把训推精度差异过大的 token 当场冻住,不让它回传梯度”,能保持稳定的强化学习训练过程,避免 GRPO 出现的训练崩溃问题,还将训推精度差异约束在合理范围内。此外,百灵大模型团队采用 Two-staged RL 方法,先通过 Long-CoT SFT 让模型 “学会思考”,再用可验证奖励的 RLVR 把推理逼到极限,最后加入 RLHF 调整格式等。虽直接融合 RLVR+RLHF 的联合训练和 Two-staged RL 效果差异不大,但从工程效率角度选择了 Two-staged RL 方案。
在性能与成本方面,大模型竞争进入 “第二幕”,核心指标变为 “谁性价比高”。Ring-flash-2.0 继承 Ling 2.0 系列的高效 MoE 设计,仅激活 6.1B 参数,即可等效撬动约 40B dense 模型的性能。其小激活、高稀疏度的设计,在 4 张 H20 部署下实现 200+ token/s 的吞吐,大幅降低高并发场景下 Thinking 模型的推理成本,且借助 YaRN 外推可支持 128K 长上下文,随着输出长度增加,相对加速比最高可达 7 倍以上。
结语指出,大模型竞争进入 “高性价比” 时代,Ring-flash-2.0 把「Long-CoT + RL」做到工程可落地,还兼顾训练稳定性、推理成本、开源生态。若说 GPT – 4 开启 “大模型可用时代”,那 Ring-flash-2.0 或许拉开 “MoE 长思考高性价比时代” 的帷幕。 其开源地址包括 HuggingFace、ModelScope、GitHub 等平台。
原文和模型
【原文链接】 阅读原文 [ 1246字 | 5分钟 ]
【原文作者】 机器之心
【摘要模型】 doubao-1-5-pro-32k-250115
【摘要评分】 ★★☆☆☆


相关文章


