文章摘要
【关 键 词】 大模型、强化学习、测试时训练、科学发现、熵目标函数
斯坦福大学、英伟达等机构的研究团队提出了一种名为TTT-Discover的创新方法,为大模型的持续学习开辟了新路径。该方法基于开源模型gpt-oss-120b,在数学、算法、生物等多个领域实现了超越人类专家和闭源前沿模型的性能表现。其核心突破在于将强化学习机制引入测试阶段,通过实时更新模型权重,使模型能够从具体问题的失败尝试中积累经验,实现定向能力进化。
传统方法依赖”测试时缩放”技术,仅通过提示调度冻结模型参数,而TTT-Discover则采用完全不同的技术路线。该方法构建了”生成-评估-更新”的闭环学习系统:模型针对单个问题生成解决方案,接收环境反馈评分,并立即调整参数以优化后续表现。这种机制使得模型能够为每个特定问题构建专属的”私有数据集”,有效解决了分布外问题缺乏训练数据的困境。在具体实现上,系统循环执行四个关键步骤:从缓冲区选择潜力方案、生成新尝试、评估结果、更新模型权重,最终输出单一最优解。
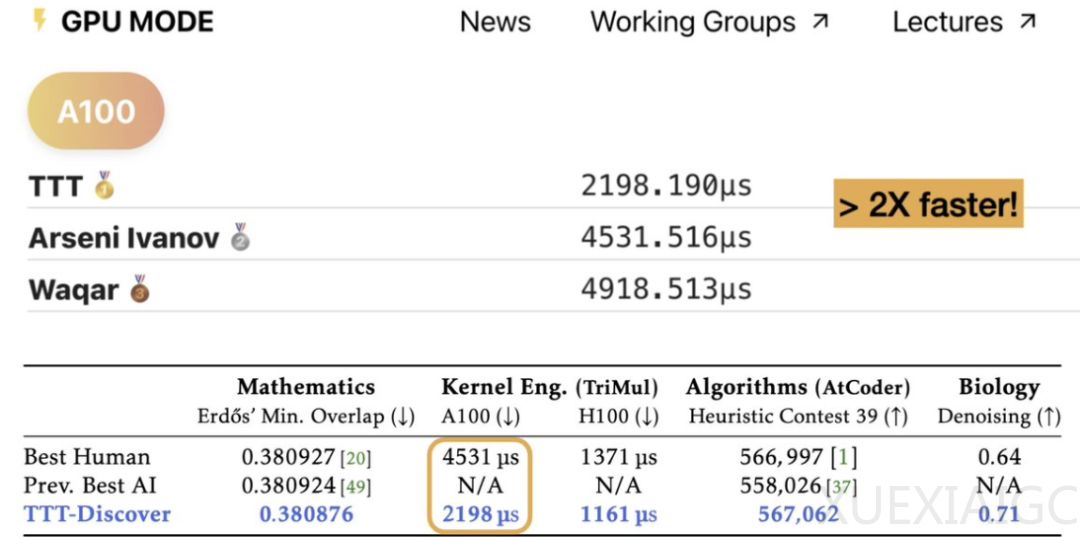
研究团队针对科学发现任务的特点,对传统强化学习框架进行了两项关键改进。首先是采用熵目标函数替代常规的平均奖励优化,使模型聚焦于寻找极优解而非多个平庸方案。其次引入受PUCT算法启发的状态选择机制,通过最大化子节点奖励的评估标准,更高效地平衡探索与利用的矛盾。这些创新使模型既能快速逼近性能极限,又避免陷入局部最优,在kernel工程任务中实现了比人类顶级工程师快2倍的速度优势。
该方法在算法层面实现了”边实战边学习”的突破性机制:模型通过自身产生的海量尝试数据(包括大量失败记录)持续优化,完全摆脱了对预设训练数据的依赖。实验显示,这种测试时训练策略使中等规模开源模型展现出解决复杂科学问题的卓越能力,特别是在Erdős最小重叠问题新界的推导、单细胞RNA-seq去噪等任务中达到最先进水平。不过目前该方法仍局限于连续可验证奖励场景,对稀疏奖励、二元奖励等问题的适用性仍有待后续研究拓展。
该研究的核心贡献者包括斯坦福大学博士生Mert Yuksekgonul和SAIL研究员Daniel Koceja,通讯作者为同时任职于斯坦福和英伟达的Yu Sun博士。研究团队特别指出,TTT-Discover的成功验证了测试时训练范式的巨大潜力,为AI系统在开放科学问题中的自主探索能力发展提供了重要技术路径。当前单个问题的测试成本约为数百美元,随着技术优化,这种方法有望在更多需要创造性解决方案的领域产生突破性影响。
原文和模型
【原文链接】 阅读原文 [ 1888字 | 8分钟 ]
【原文作者】 量子位
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★☆


相关文章


