文章摘要
【关 键 词】 OCR、开源模型、文本识别、表格解析、结构化提取
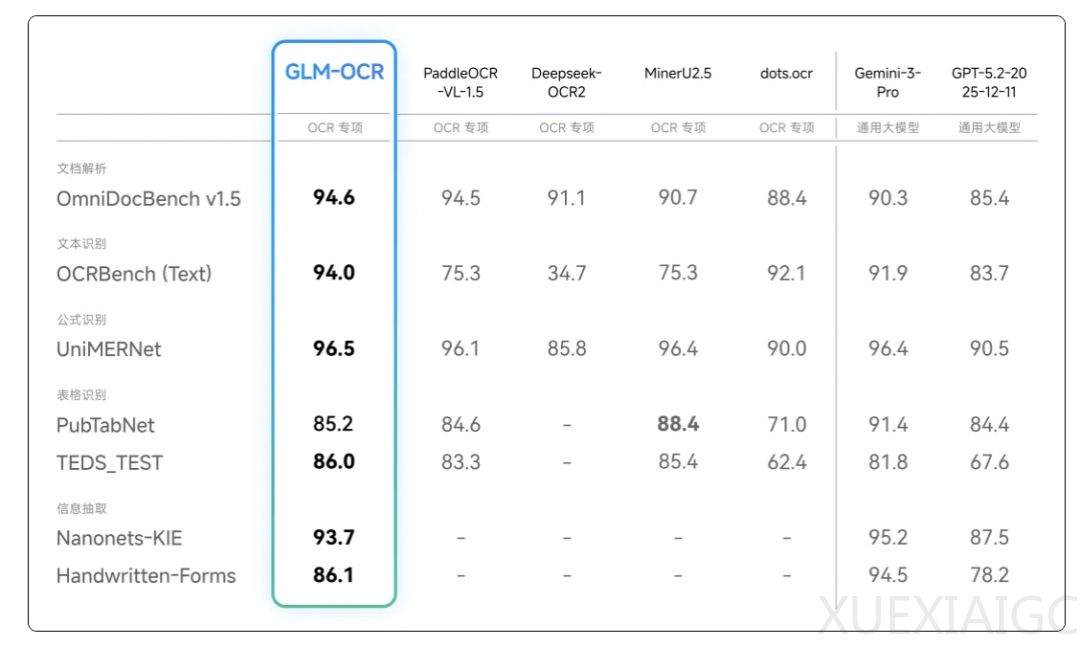
GLM-OCR开源模型在OCR领域展现出显著的技术突破与应用潜力。该模型虽仅0.9B参数,却在OmniDocBench V1.5榜单上达到SOTA水平,性能超越Gemini-3-Pro和GPT5.2等大型模型。其核心能力覆盖三大场景:通用文本识别支持照片、扫描件等多形态输入,能处理手写体、代码等特殊内容;复杂表格解析可精准还原合并单元格等结构并输出HTML;结构化提取功能则能从票据、证件中智能抽取字段生成JSON。
在实测环节,手写体识别准确率达96%,虽存在将潦草”X”误判为”=”等错误,但表现仍优于对比测试的GPT-5.2。代码解析场景中,模型能自动切换至代码模式,近乎完美还原符号密度极高的编程语言内容。印章识别和低质量输入测试中,即便面对模糊图像也能保持较高识别率,仅个别文字出现偏差。表格解析方面,模型对财务数据等数值内容识别精准,但存在表头误判导致行列错位的结构性缺陷。
当前OCR技术发展呈现三大趋势:参数轻量化(0.07B-1B规模)、多场景识别能力提升、成本与速度持续优化。GLM-OCR作为典型代表,其开源特性与完整工具链支持(含vLLM/Ollama部署方案)显著降低了使用门槛。不过在实际应用中,复杂排版解析和极端潦草字迹仍是技术瓶颈,需要结合提示词约束或后续人工校验来保证输出质量。
该模型最适合处理格式规整的文档、清晰手写体及日常会议纪要等标准化场景。其SDK开放性和部署灵活性为开发者提供了丰富的二次开发空间,而持续降低的API成本也加速了OCR技术在各行业的普及进程。随着百度PP-OCRv5、DeepSeek-OCR2等竞品的迭代,国内OCR领域已形成技术竞逐态势,最终推动整体解决方案向更高效、更经济的方向发展。
原文和模型
【原文链接】 阅读原文 [ 2781字 | 12分钟 ]
【原文作者】 量子位
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★☆


相关文章


