文章摘要
【关 键 词】 AI模型、开源轻量、编程助手、MoE架构、本地部署
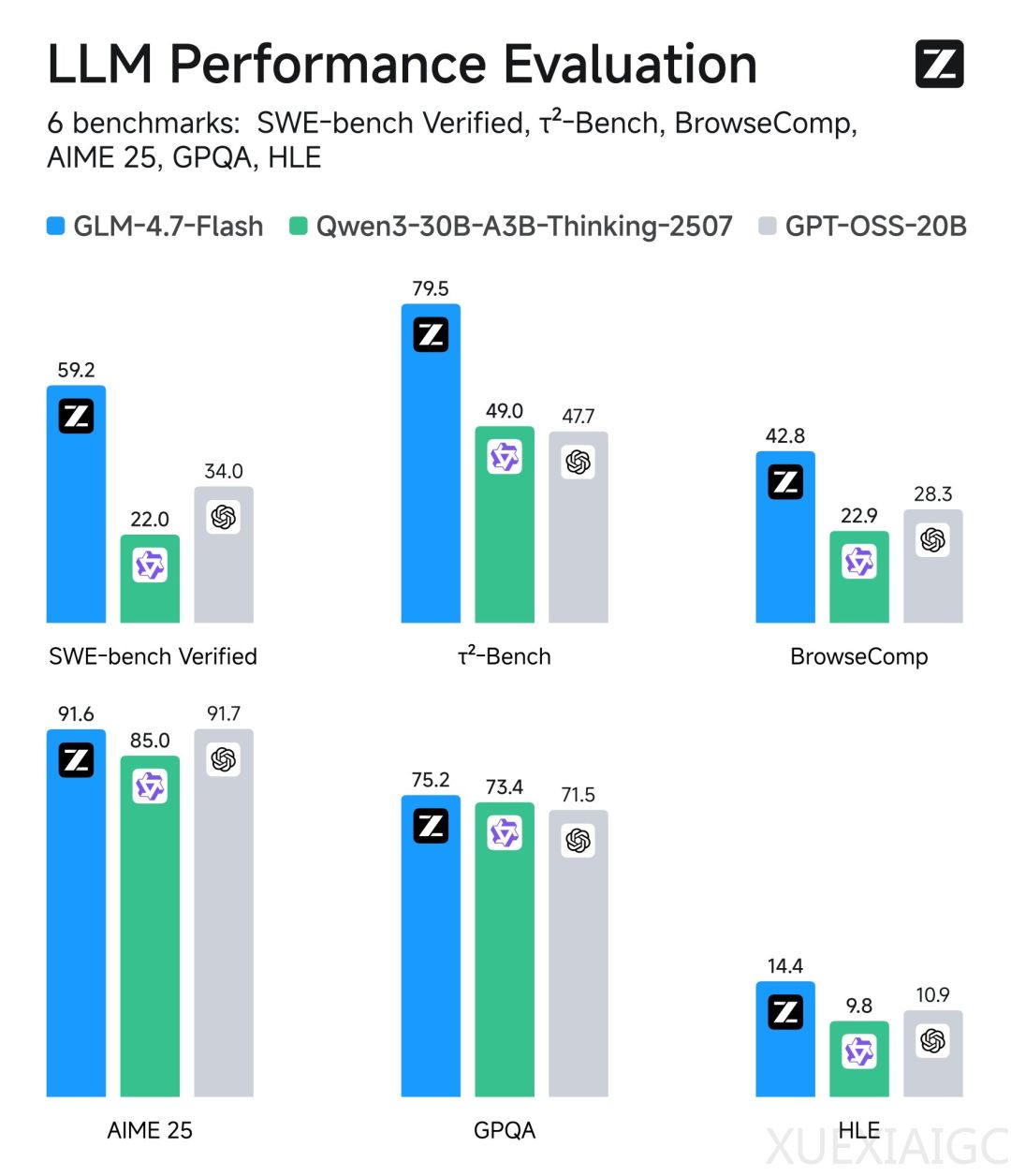
智谱AI近期推出开源轻量级大语言模型GLM-4.7-Flash,作为GLM-4.5-Flash的升级版本,该模型采用混合专家(MoE)架构,总参数量达30B但仅激活3B参数,显著提升计算效率。官方定位其为”本地编程与智能体助手”,在SWE-bench Verified代码修复测试中以59.2分表现突出,超越同类规模的Qwen3-30B和GPT-OSS-20B模型。
技术架构方面,该模型首次采用MLA(Multi-head Latent Attention)注意力机制,借鉴了DeepSeek-v2的已验证方案。其64专家系统中每次仅调用5个专家的设计,配合200K长上下文窗口支持,既适用于云端API调用也适配本地部署场景。开发者实测显示,在配备32GB统一内存的M5芯片苹果笔记本上能达到43 token/s的推理速度。
应用场景覆盖编程辅助、创意写作、翻译及角色扮演等多领域。官方API平台提供完全免费的基础版服务(限1并发),高速版定价也具竞争优势。相比同类产品,其在上下文长度支持和token输出成本方面存在优势,但当前版本在延迟和吞吐量性能上仍需优化。
生态适配方面表现亮眼,发布12小时内即获得HuggingFace、vLLM等主流平台的原生支持,并同步提供对华为昇腾NPU的兼容。技术细节虽未完全公开,但配置文件显示其深度设计与GLM-4.5 Air保持相近,专家数量配置则区别于Qwen3-30B-A3B的128专家方案。这种平衡性能与效率的设计思路,为轻量化模型部署提供了新的实践参考。
原文和模型
【原文链接】 阅读原文 [ 563字 | 3分钟 ]
【原文作者】 量子位
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★☆☆☆☆


相关文章


