文章摘要
【关 键 词】 蚂蚁开源、万亿参数、语言模型、推理能力、代码生成
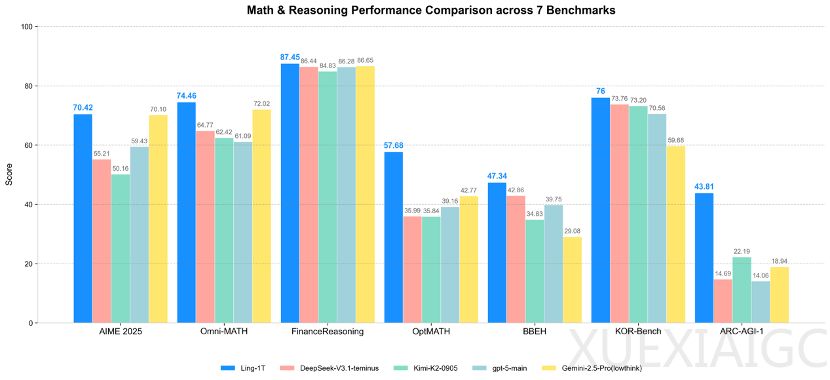
蚂蚁集团正式发布其百灵大模型系列的首款旗舰产品——拥有万亿参数的通用语言模型Ling-1T。该模型在多项复杂推理基准测试中超越主流开源与闭源模型,包括DeepSeek-V3.1-Terminus、GPT-5-main等,尤其在代码生成、数学竞赛、逻辑推理等任务中取得当前最优表现。其显著特点是推理速度极快,能够即时响应复杂问题,并保持长文本生成的流畅性。
在具体能力展示中,Ling-1T展现出多维度优势。面对空间几何优化问题,模型不仅能提出四种可行性方案,还会对每种方法进行物理条件验证和风险评估。在解决概率论领域的”外星人分裂”问题时,模型迅速建立数学模型并推导出精确答案√2-1。实际应用场景测试同样亮眼:构建诺贝尔奖介绍网站时,模型自动实现模块化信息架构;规划旅游路线时,能整合交通、餐饮等多元要素并生成结构化方案。
技术实现层面,研究团队通过”中训练+后训练”结合的演进式思维链(Evo-CoT)方法突破传统局限。模型采用1万亿参数规模,其中每个token激活约500亿参数,预训练阶段使用超过20T token的高质量语料,支持128K长上下文窗口。训练策略上创新性地采用三阶段设计:先用高知识密度语料打基础,再通过高推理密度语料培养逻辑能力,最后通过中间训练强化思维链推理。团队研发的WSM学习率策略和LPO优化方法,有效解决了大模型训练中的语义碎片化与奖励信号失衡问题。
这一开源动作标志着中国大模型技术进入新阶段。Ling-1T不仅以”语法-功能-美学”混合奖励机制在ArtifactsBench基准中夺冠,其非传统架构设计更为行业提供了新范式。随着Qwen、DeepSeek等国产模型持续迭代,蚂蚁的加入进一步巩固了中国在开源生态的领先地位。当前行业竞争态势显示,国内厂商正通过快速的技术突破和密集的开源节奏,持续推动大模型能力边界扩展。
原文和模型
【原文链接】 阅读原文 [ 3026字 | 13分钟 ]
【原文作者】 量子位
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★☆


相关文章


