文章摘要
【关 键 词】 人工智能、内存瓶颈、硬件性能、模型训练、神经网络
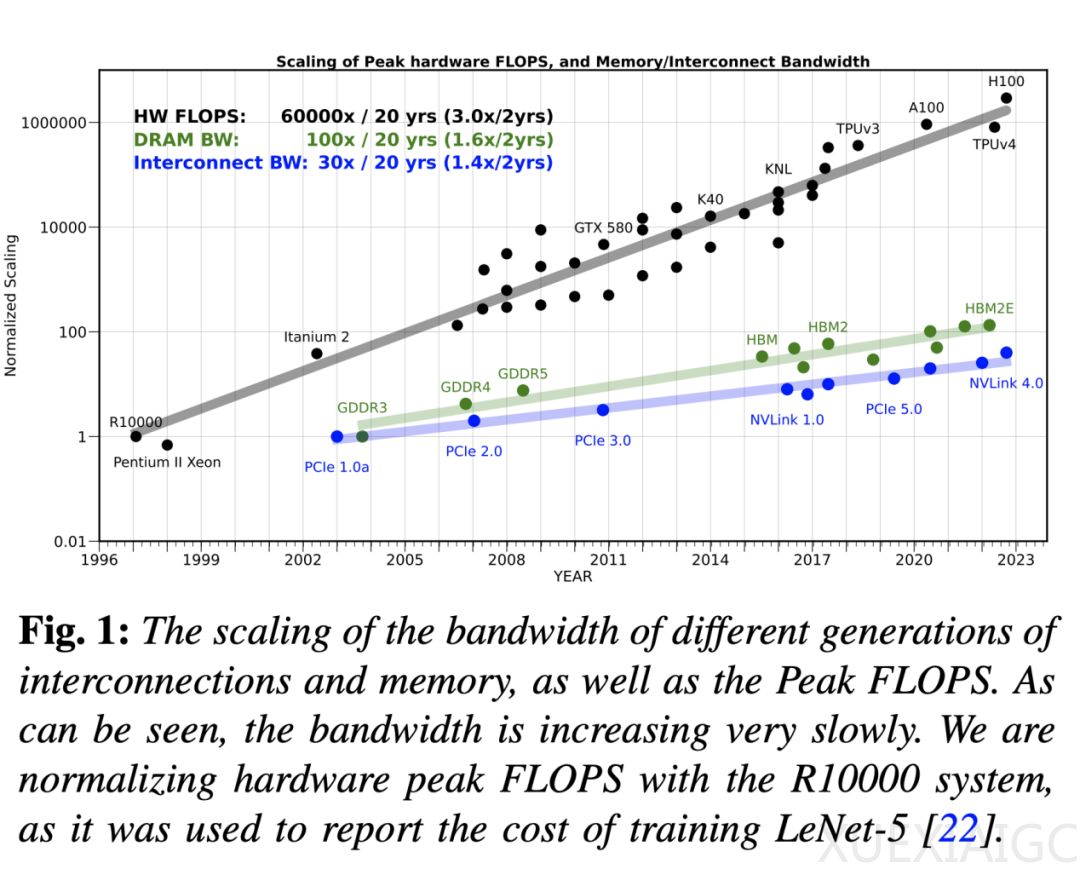
近年来,训练大型语言模型的计算需求呈指数级增长,但硬件性能的提升主要集中在峰值计算能力上,而内存带宽的增长速度远远落后。这种差距导致内存成为人工智能应用,尤其是模型服务的主要瓶颈。过去20年,服务器硬件的峰值浮点运算能力(FLOPS)以每两年3倍的速度增长,而DRAM和互连带宽仅分别增长1.6倍和1.4倍。这种趋势被称为“内存墙”问题,最早在1990年代就被预测,如今在人工智能领域愈发显著。
Transformer模型的内存瓶颈尤为突出。解码器架构(如GPT)的自回归推理涉及大量矩阵-向量运算,其内存操作量远高于编码器架构(如BERT)。实验表明,即使两者的计算量(FLOPs)相近,解码器模型的延迟显著更高,这直接归因于其更低的算术强度(即内存带宽利用率)。这种差异凸显了内存带宽对模型性能的关键影响。
突破内存瓶颈需要多方面的创新。首先,模型设计需更高效,避免简单扩展现有架构。当前的大型Transformer模型大多基于BERT的原始设计,缺乏根本性改进。其次,训练算法需优化,例如采用二阶随机优化方法或重物化技术,以减少内存占用。此外,部署阶段可通过量化、剪枝或开发小型语言模型来降低资源需求。例如,量化可将推理精度降至INT4,减少8倍内存占用,而剪枝能移除高达80%的非关键参数。
硬件设计也需重新平衡计算与内存性能。现有加速器过于侧重峰值计算能力,牺牲了缓存和内存层次结构。未来架构可能需要折中方案,例如优化缓存或引入更高容量的DRAM层次结构,以缓解分布式内存的通信瓶颈。CPU在带宽受限任务中表现优于GPU,正因其缓存优化,但其计算能力仍需提升。
总体来看,内存墙问题已成为人工智能发展的核心挑战。随着模型规模和计算需求的持续增长,内存带宽的限制将更加严峻。解决这一问题需要算法、模型架构和硬件设计的协同创新,否则成本和技术瓶颈可能阻碍人工智能的进一步突破。
原文和模型
【原文链接】 阅读原文 [ 5123字 | 21分钟 ]
【原文作者】 半导体行业观察
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章


