文章摘要
【关 键 词】 递归语言模型、超长文本处理、上下文腐烂、模型推理、编程环境
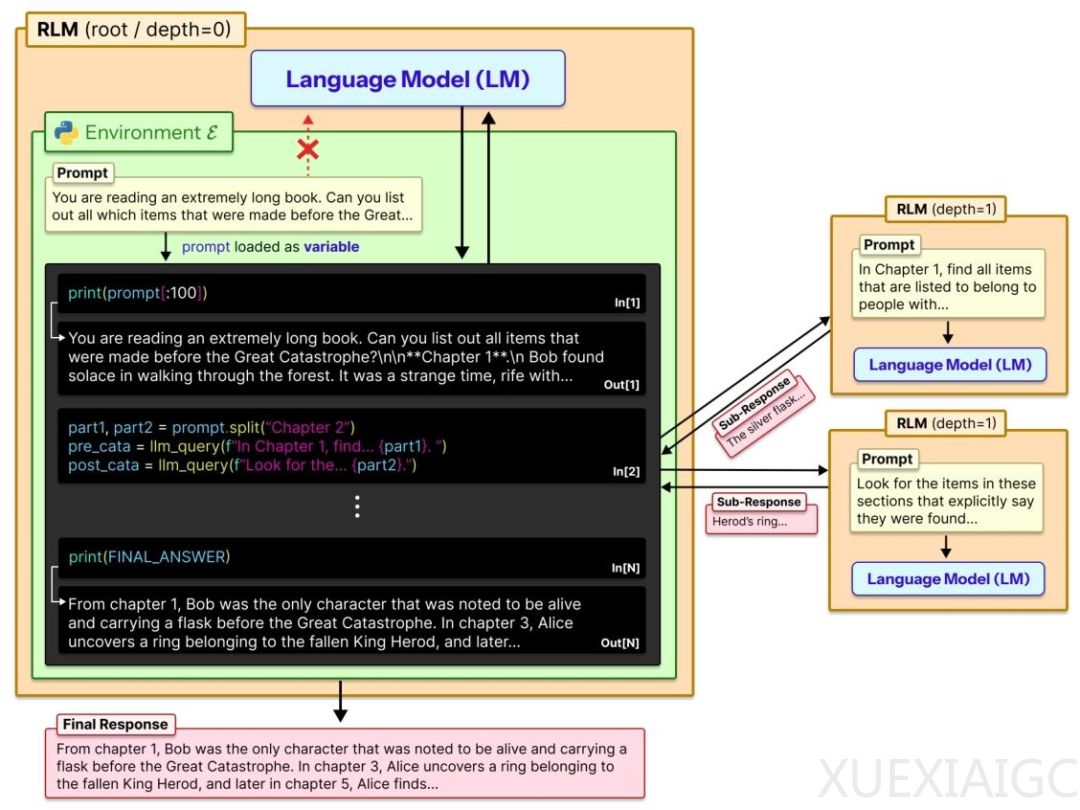
MIT CSAIL研究团队提出了一种名为递归语言模型(RLM)的创新方法,旨在解决大模型处理超长文本时的上下文腐烂问题。该方法无需修改模型架构或升级模块设计,即可让GPT-5、Qwen-3等顶尖模型具备处理千万级Token超长文本的能力。核心思路是将提示词“外包”给可交互的Python环境,通过自动编程和递归调用实现任务的动态拆解与按需处理。
当前大模型面临的核心挑战是上下文窗口限制导致的性能衰减。无论模型宣称的上下文窗口多大,超长文本都会引发早期信息记忆模糊和推理能力下降。这种现象类似于阅读百万字小说时遗忘前半段关键情节。现有解决方案包括上下文压缩、检索增强生成(RAG)和架构级优化,但这些方法均需直接修改模型本身。RLM的突破性在于完全绕开模型改造,转而利用外部编程环境实现文本处理。
RLM的工作机制分为四个关键阶段:首先启动Python REPL环境存储原始文本;随后模型自主编写代码进行文本预处理;接着递归调用子模型处理分块内容;最后整合子任务结果生成最终输出。这种“编程-执行-反馈”的闭环设计使模型能动态调整信息处理策略,彻底解耦文本长度与上下文窗口的绑定。实验数据显示,RLM在600万至1100万Token的多文档推理任务中正确率达91.33%,远超传统方法。
在具体任务表现上,RLM展现出显著优势。面对复杂度呈二次方增长的OOLONG-Pairs任务,RLM将GPT-5的F1分数从不足0.1%提升至58.00%。成本分析表明,RLM在常规任务中与其他方案持平甚至更低,但在高复杂度任务中因动态递归调用可能导致成本上升。这种成本波动源于模型自主决策产生的额外API调用,属于性能提升的合理代价。
技术层面,RLM的最大价值在于其通用性。作为纯推理层策略,它理论上兼容所有现有模型,无需重新训练或架构调整。该方法不仅突破了长文本处理的技术瓶颈,更开创了“模型+编程环境”的新型交互范式。未来随着自动编程能力的提升,RLM或将成为大模型处理超复杂任务的标准化解决方案。
原文和模型
【原文链接】 阅读原文 [ 1068字 | 5分钟 ]
【原文作者】 量子位
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★☆☆☆


相关文章


