文章摘要
【关 键 词】 AI计算、存储技术、半导体、高带宽、能效优化
近年来,AI与高性能计算的迅猛发展推动了对计算需求的指数级增长。从ChatGPT到Sora,大规模AI模型的参数规模和计算需求呈现爆发式增长,但存储器的性能瓶颈——“存储墙”问题日益凸显。存储带宽成为制约AI计算吞吐量与延迟的核心瓶颈,传统存储器技术已难以满足系统能效优化的需求。台积电在2025年的IEDM教程中指出,未来AI芯片的竞争将不仅是晶体管密度与频率的竞赛,更是内存子系统性能、能效与集成创新的综合较量。
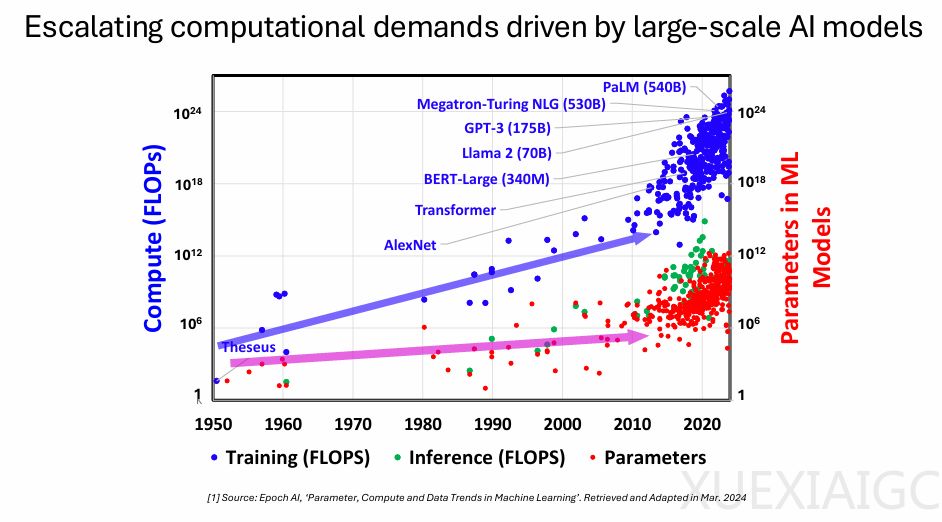
AI模型的进化对算力与存储提出了极高要求。从AlexNet到GPT-4,模型参数从百万级跃升至万亿级,训练计算量增长超过10^18倍。然而,计算性能与存储器带宽的增长速度严重失衡,硬件峰值浮点运算性能在过去20年间增长了60000倍,而DRAM带宽仅增长100倍。这种失衡导致AI推理中大量计算资源因等待数据而闲置,存储器带宽成为限制计算吞吐量的主要瓶颈。以英伟达H100 GPU为例,其峰值计算性能达989 TFLOPs,但峰值带宽仅3.35 TB/s,系统性能常陷入存储受限状态。
为应对这一挑战,存储器技术需同时满足大容量、高带宽和低数据传输能耗三大核心指标。传统计算为中心的架构正加速向存储为中心转型,高密度、低能耗的嵌入式存储器成为技术突破的关键方向。台积电提出“存储-计算协同”的演进路径,从传统片上缓存逐步发展为存算一体与近存计算,通过存储与计算的深度融合突破性能与能效瓶颈。分层存储架构成为平衡速度、带宽、容量与功耗的主流方案,SRAM缓存、HBM与DRAM主存以及SSD存储设备各司其职。
SRAM作为高速嵌入式存储器的核心方案,凭借低延迟、高带宽等优势成为寄存器与缓存的首选技术。但随着工艺节点向7nm以下演进,SRAM面临面积缩放速度放缓、最小工作电压优化困境和互连损耗加剧等挑战。台积电通过设计-工艺协同优化(DTCO)策略和3D堆叠V-Cache技术应对这些挑战。例如,AMD Ryzen 7 5800X3D处理器通过3D堆叠技术集成96MB共享L3缓存,显著提升了游戏性能。
存内计算(CIM)则是一场更具颠覆性的架构革命,通过减少数据搬运大幅提升能效比。在AI加速器中,超过90%的能耗用于数据搬运而非实际计算。台积电认为,数字存内计算(DCiM)相比模拟存内计算(ACiM)更具发展潜力,因其无精度损失、灵活性强且兼容先进工艺。DCiM支持多精度计算,INT8精度下的能效比相比传统架构提升约4倍,成为边缘推理场景的理想解决方案。
磁阻随机存取存储器(MRAM)凭借非易失性、高密度等优势,成为嵌入式非易失性存储器的理想替代方案。MRAM在汽车电子和边缘AI场景中展现出独特价值,支持OTA更新和紧凑AI架构。台积电通过数据擦洗技术和抗磁性干扰设计优化MRAM的可靠性,其N16工艺的嵌入式MRAM技术已满足汽车应用的严苛要求。
未来,AI与HPC时代的存储技术突破将走向系统级的计算-存储融合。3D封装与芯粒集成技术将成为关键赋能,通过缩短存储与计算单元的物理距离,实现带宽和能效的阶跃式提升。台积电的CoWoS和SoIC等先进封装技术,将逻辑芯片与HBM高密度集成,支撑AI内存高达20.0TB/s的带宽需求。这种系统级优化要求芯片设计者、存储器专家和封装工程师从架构设计之初就紧密协作,通过内存-计算协同优化突破存储墙与能效瓶颈。
AI计算的未来是一场围绕数据效率的革命,存储技术正进入全维度创新的新时代。台积电的技术蓝图描绘了从SRAM到DCiM,再到3D封装的全面演进路径,为行业突破“存储墙”提供了清晰的解决方案。在这场竞争中,全栈优化能力将成为引领AI算力下一个黄金时代的关键。
原文和模型
【原文链接】 阅读原文 [ 4811字 | 20分钟 ]
【原文作者】 半导体行业观察
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章


