文章摘要
【关 键 词】 多模态大模型、视觉思维链、视觉语言模型、空间感知、人工智能
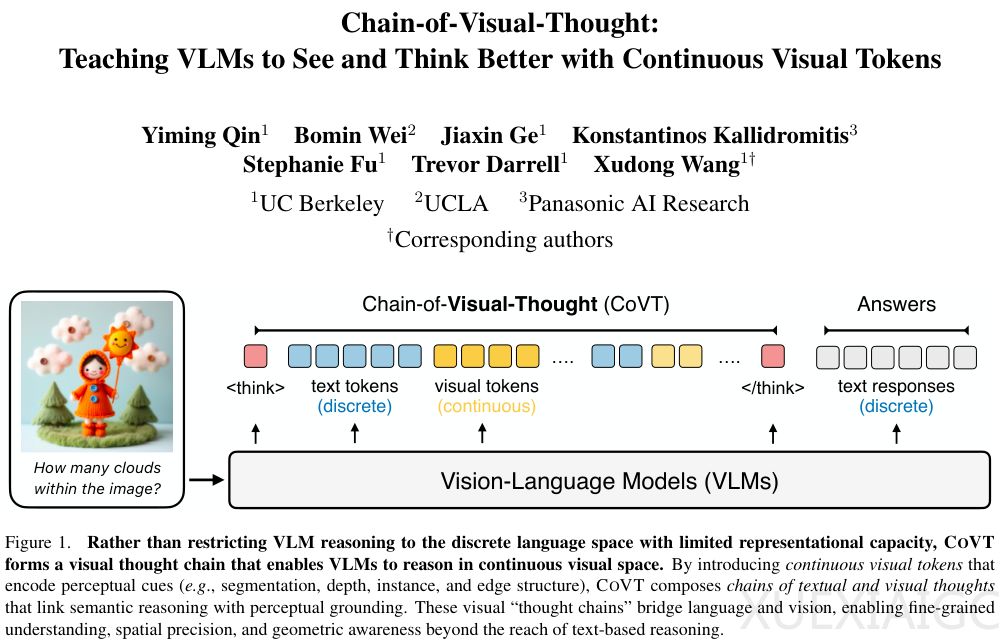
加州大学伯克利分校团队提出了一种名为视觉思维链(CoVT)的全新架构,旨在解决多模态大模型在处理视觉信息时被迫将其翻译成文本的局限性。人类通过视觉信号直接建立空间感,而传统视觉语言模型(VLMs)将连续、高维的视觉信息压缩为离散的文本符号,导致关键感知细节的流失。这种“视觉翻译”在处理需要精确感知的任务时尤为明显,例如计数或距离判断,甚至可能因文本描述的不准确而产生幻觉。
CoVT架构的核心创新在于允许模型在推理过程中生成连续的视觉Token,而非仅依赖文本符号。这些视觉Token通过四个轻量级专家模型(SAM、DepthAnything v2、PIDINet和DINOv2)的训练内化为模型的直觉能力,分别对应物体分割、深度估计、边缘检测和语义理解。模型在训练阶段预测这些专家模型的输出,从而在推理时无需外部工具即可生成富含感知信息的视觉Token。这种设计既保留了端到端模型的高效性,又融合了专用视觉工具的精细感知能力。
CoVT采用了一套针对性的对齐策略,确保视觉Token与实际图像特征一致。对于任务导向型模型(如SAM、DepthAnything),采用Prompt级对齐,将视觉Token转化为提示符输入解码器以还原图像;对于表征型模型(如DINOv2),则采用特征级对齐,直接映射抽象特征。训练过程分为四个阶段:理解、生成、推理和高效推理,逐步引导模型掌握视觉思维链的运用。
实验结果表明,CoVT在视觉感知任务上表现显著优于传统方法。在CV-Bench测试中,集成视觉Token的模型整体得分提升5.3%,深度子任务得分暴涨16.4%。在计数和距离判断等传统难题上,CoVT甚至超越了闭源的Claude-4-Sonnet和GPT-4o。此外,视觉思维的加入不仅未干扰语言能力,反而在纯文本任务中带来微弱提升。CoVT还提供了前所未有的可解释性,通过解码视觉Token可直观理解模型的推理过程,例如在深度判断或物体计数任务中,模型生成的视觉Token清晰反映了其决策依据。
研究进一步揭示,纯文本思维链在视觉任务中可能适得其反,而视觉思维链更接近人类的多模态思维模式。这一发现为人工智能的发展指明了方向:智能的形式不应局限于语言,而应结合直觉式感知与逻辑推理,迈向更高级的通用智能。
原文和模型
【原文链接】 阅读原文 [ 3464字 | 14分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章


