文章摘要
【关 键 词】 AI技术、语音识别、多语言处理、文化保护、开源生态
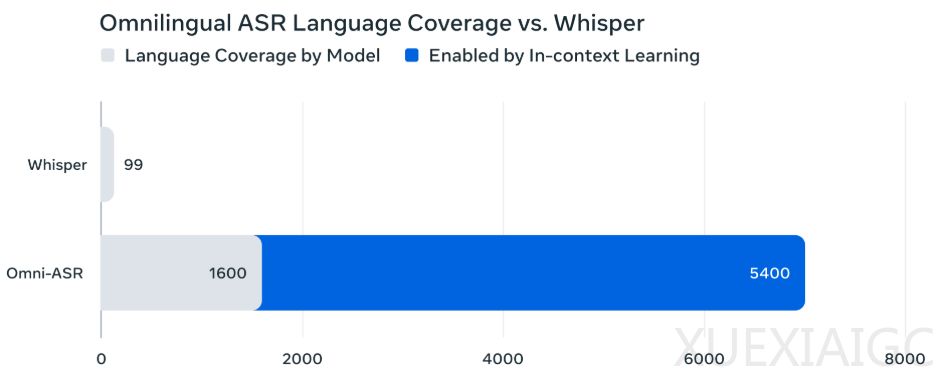
Meta AI发布的Omnilingual ASR技术标志着自动语音识别领域的重大突破。该系统首次实现对1600多种语言的转录能力,其中500多种语言是历史上首次被AI系统记录。这一进展打破了数字世界中语言不平等的技术壁垒,全球7000多种语言中绝大多数长期处于技术边缘化的状态。
传统ASR技术依赖海量标注数据,导致低资源语言难以被有效支持。尽管此前Facebook的wav2vec 2.0和Google的USM模型通过自监督学习将支持语言扩展到100种以上,但这些系统仍存在扩展性差、新增语言需重复训练、社区参与门槛高等根本性缺陷。Omnilingual ASR通过架构创新彻底改变了这一范式,其核心由70亿参数的编码器和LLM风格解码器组成。编码器基于430万小时多语言音频的自监督学习,形成对语音声学特征的普适理解;解码器则采用类似GPT的生成式架构,通过上下文学习实现零样本迁移。
关键技术突破体现在零样本上下文学习机制。系统仅需3-5对目标语言的音频-文本样本,即可在不调整模型参数的情况下实现新语言的高质量转录。配合SONAR多模态编码器的智能检索功能,该方案将低资源语言的转录准确率提升15%-20%。这种设计使得语言支持上限理论上可达5400种,且扩展工作可由普通社区用户完成。
数据采集方式同样具有革新意义。120,710小时的有标签数据集AllASR包含1690种语言,其中专为低资源语言构建的Omnilingual ASR Corpus采用社区参与式采集,通过母语者自然叙述获取348种语言的3350小时语音。这些数据以CC-BY-4.0协议开放,成为保护语言多样性的重要资源。
性能测试显示,7B参数的omniASR_LLM模型在FLEURS 102等基准测试中全面超越现有系统。其字符错误率(CER)在1600多种语言上达到SOTA水平,且支持语言数量是Google USM的16倍。更重要的是,该技术构建了完全开源的生态系统,模型、数据和代码均开放,使语言技术的民主化发展成为可能。这项突破不仅重新定义了多语言ASR的技术边界,更为濒危语言的数字化保存提供了切实可行的解决方案。
原文和模型
【原文链接】 阅读原文 [ 2293字 | 10分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章


