Agent「记吃不记打」?华为诺亚&港中文发布SCOPE:Prompt自我进化,让HLE成功率翻倍
文章摘要
【关 键 词】 LLM Agent、错误循环、自我进化、华为诺亚方舟、香港中文大学
在LLM Agent领域,一个普遍存在的问题是Agent无法从错误中有效学习,导致重复相同的错误。华为诺亚方舟实验室与香港中文大学联合发布的SCOPE框架,通过动态优化Prompt设计,使Agent能够从执行轨迹中自动提炼指导规则,实现自我进化。
研究发现Agent失败主要分为两类:纠正型失败和增强型失败。前者指Agent无法利用错误信息中的明确纠正信号,后者则表现为Agent错过潜在的优化机会。这两种失败模式的根本原因在于静态Prompt缺乏从执行反馈中学习的机制。SCOPE框架通过四个核心组件解决这一问题:指导规则合成、双流路由机制、记忆优化和视角驱动探索。
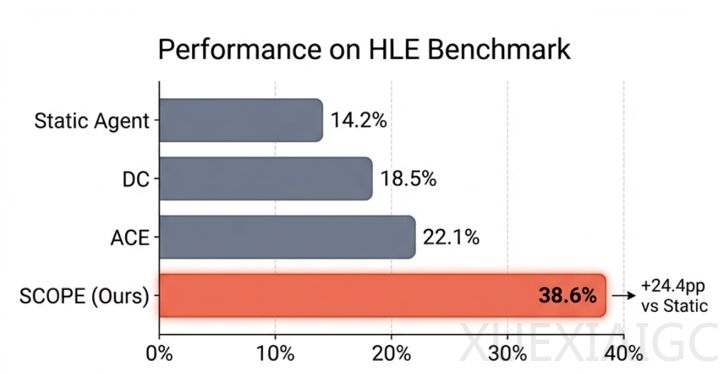
实验结果显示,SCOPE显著提升了Agent的任务成功率。在HLE基准上,成功率从14.23%提升到38.64%;在GAIA基准上,从32.73%提升到56.97%。特别是在知识密集型领域(如生物/医学、化学),提升更为显著。消融实验表明,视角驱动探索贡献了最大的性能提升(+10.91%)。
SCOPE的关键创新在于实现了Agent的实时适应能力。研究观察到”语言采纳”现象,即Agent在规则合成后立即调整行为。双流路由机制将规则分为战术记忆(任务特定)和战略记忆(跨任务通用),确保学习到的经验得到有效应用。
框架的实用性体现在即插即用设计和模型无关性。开发者只需调用`on_step_complete()`接口即可为现有系统添加自我进化能力,无需修改架构。SCOPE支持多种模型提供商,并通过轻量级部署简化集成过程。
视角驱动探索策略验证了多进化路径的价值。效率流和周全流虽然总体准确率相近,但解决的问题重合度仅为33.94%,表明不同策略具有互补优势。这种设计使SCOPE能够同时处理时间紧迫型和深度检索型任务。
SCOPE代表了LLM Agent发展的新方向:将Prompt视为可进化参数而非静态模板。其步级别适应能力和主动优化特性(61%的规则来自成功模式的增强型合成)为下一代Agent系统设计提供了重要参考。开源实现的可扩展性和易用性进一步降低了研究者和开发者的应用门槛。
原文和模型
【原文链接】 阅读原文 [ 2258字 | 10分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章


