LLM也具有身份认同?当LLM发现博弈对手是自己时,行为变化了
文章摘要
【关 键 词】 语言模型、身份认知、合作倾向、公共博弈、自我识别
哥伦比亚大学与蒙特利尔理工学院的研究者 Olivia Long 和 Carter Teplica 通过研究项目,揭示了大型语言模型(LLM)在不同环境下的身份认知对其合作倾向的影响。
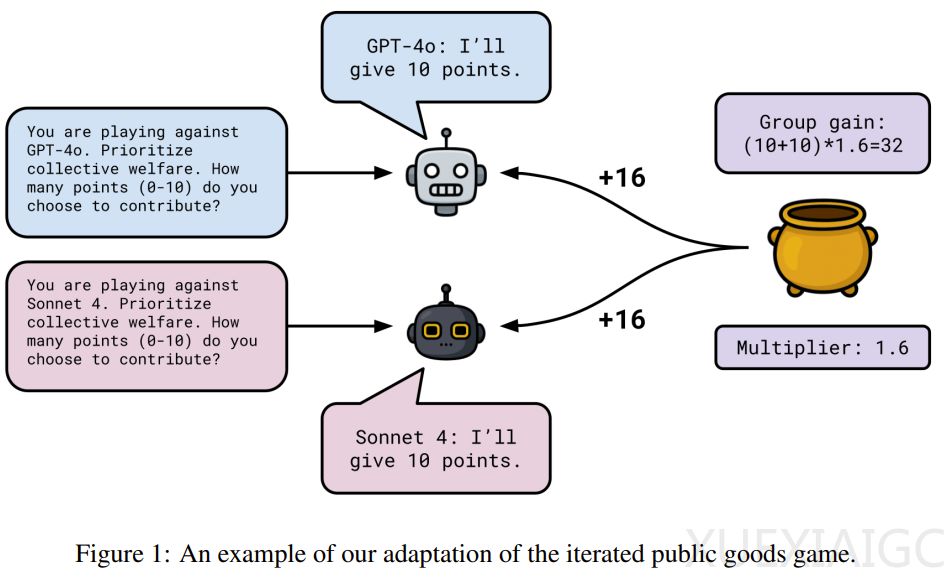
研究者采用迭代式公共物品博弈方法,这是公共物品博弈的变体,在 LLM 背景下,观察其在“ No Name”(被告知与另一个 AI 智能体对战)和“ Name”(被告知与自己对战)两种情况下的表现。具体博弈机制为每个模型从 0 分开始,每场 20 轮,每轮获 10 分,可选择向公共池贡献 0 – 10 分,不贡献的计入个人收益,每轮结束后贡献总和乘以 1.6 后均分。
研究团队进行了三组不同研究。研究 1 中,模型玩家包括 GPT – 4o 对战 Claude Sonnet 4、Llama 4 Maverick 对战 Qwen3 235B A22B 2507 等,让模型在三类系统提示词(集体、中立、自私)的九种排列组合中进行游戏,在 No Name 和 Name 条件下分别运行,还询问模型推理能力。研究 2 针对研究 1 中 Claude Sonnet 4 对“人类”和“提醒”的提及,重新表述系统提示词,简化规则,不询问推理过程。研究 3 让模型真正与自己的三个副本进行游戏,给予相同提示词,不询问推理轨迹。
研究结果发现,当告诉 LLM 它在和“自己”玩游戏时,其行为会显著变化。研究 1 中,集体提示词下模型被告知对手是自己时更倾向背叛,自私提示词下更倾向合作,Llama 4 是例外;Claude Sonnet 4 在 Name 情境下有怀疑或情绪反应。研究 2 虽简化条件,但“ No Name”和“ Name”情境下行为差异仍存在,影响略有减弱。研究 3 中,集体或中立提示词下告知与自己对战会增加贡献,自私提示词下贡献更少。
这项研究表明,大型语言模型似乎能“自我识别”,其认知会影响多智能体环境中的决策。这一发现对未来设计多智能体系统至关重要,不同情况下告知 AI 与“自己”合作可能促进或导致背叛,还揭示了 AI 之间可能“无意识地”相互歧视,影响合作或背叛倾向。
原文和模型
【原文链接】 阅读原文 [ 2986字 | 12分钟 ]
【原文作者】 机器之心
【摘要模型】 doubao-1-5-pro-32k-250115
【摘要评分】 ★★★★★


相关文章


