「Next-Token」范式改变!刚刚,强化学习预训练来了
文章摘要
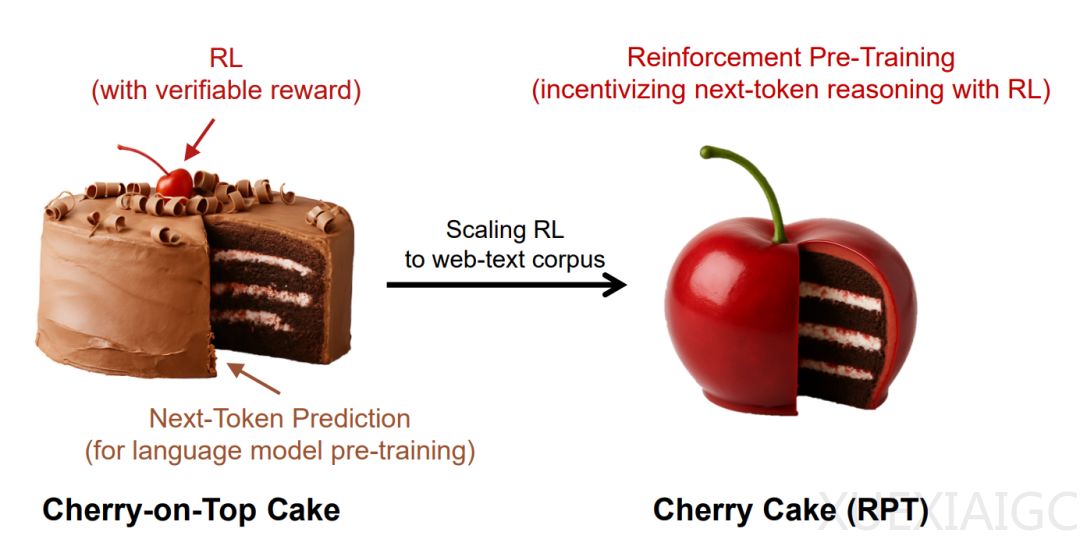
在人工智能领域,强化学习(RL)长期以来被视为提升模型能力的辅助工具,而非核心方法。然而,近年来,强化学习在提升大语言模型(LLMs)能力方面的作用逐渐凸显,尤其是在预训练阶段的应用展现出巨大潜力。微软的一项新研究提出了一种名为「强化预训练(Reinforcement Pre-Training, RPT)」的新范式,旨在弥合自监督预训练与强化学习能力之间的鸿沟。RPT将传统的下一个token预测任务重构为推理任务,通过强化学习训练模型,使其在预测下一个token时获得可验证的奖励。这种方法不仅提升了语言建模的准确性,还为后续的强化微调提供了强大的预训练基础。
RPT的核心优势在于其可扩展性和通用性。它充分利用了海量无标注文本数据,无需依赖特定领域的标注答案,即可将其转化为适用于通用强化学习的大规模训练资源。通过直接使用基于规则的奖励信号,RPT最大限度地降低了reward hacking的风险,并促使模型进行更深层次的理解和泛化,而不仅仅是记住下一个token。此外,RPT在预训练期间引入的推理过程允许模型为每个预测步骤分配更多的计算资源,类似于将推理时间扩展能力提前应用到训练过程中,从而直接提升下一token预测的准确性。
实验结果表明,RPT在多个方面表现出色。在语言建模能力测试中,RPT方法在不同难度级别的测试集上均优于标准的下一个token预测基线和基于推理的预测基线。值得注意的是,RPT-14B模型的性能甚至与规模更大的R1-Distill-Qwen-32B模型相媲美,表明RPT在捕获token生成背后的复杂推理信号方面具有显著效果。此外,RPT的scaling特性表明,随着训练计算量的增加,下一个token预测的准确性持续提升,进一步验证了其作为一种有效且前景广阔的预训练范式的潜力。
在强化微调方面,经过RPT预训练的模型在后续使用RLVR进行训练时,能够达到更高的性能上限。这表明,RPT能够快速将从下一个token推理中学到的强化推理模式迁移到下游任务中,尤其在数据有限的情况下,这种迁移能力尤为重要。此外,RPT在零样本性能测试中也表现出色,RPT-14B在所有基准测试中始终优于R1-Distill-Qwen-14B,甚至在next-token预测方面超越了规模更大的R1-Distill-Qwen-32B。
最后,RPT的next-token推理模式分析揭示了其与结构化问题解决过程的本质差异。RPT-14B的推理过程更加深思熟虑,而非简单的模式匹配,这表明RPT能够引导模型进行更复杂的推理,从而提升其整体性能。总体而言,RPT作为一种新型的预训练范式,不仅在语言建模和推理能力方面表现出色,还为强化学习在LLM训练中的广泛应用提供了新的思路和可能性。
原文和模型
【原文链接】 阅读原文 [ 2138字 | 9分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek-v3
【摘要评分】 ★★★★★


相关文章


