万字长文解析OpenAI o1 Self-Play RL技术路线
文章摘要
【关 键 词】 Self-Play RL、推理能力、多模态模型、技术路线、创新性
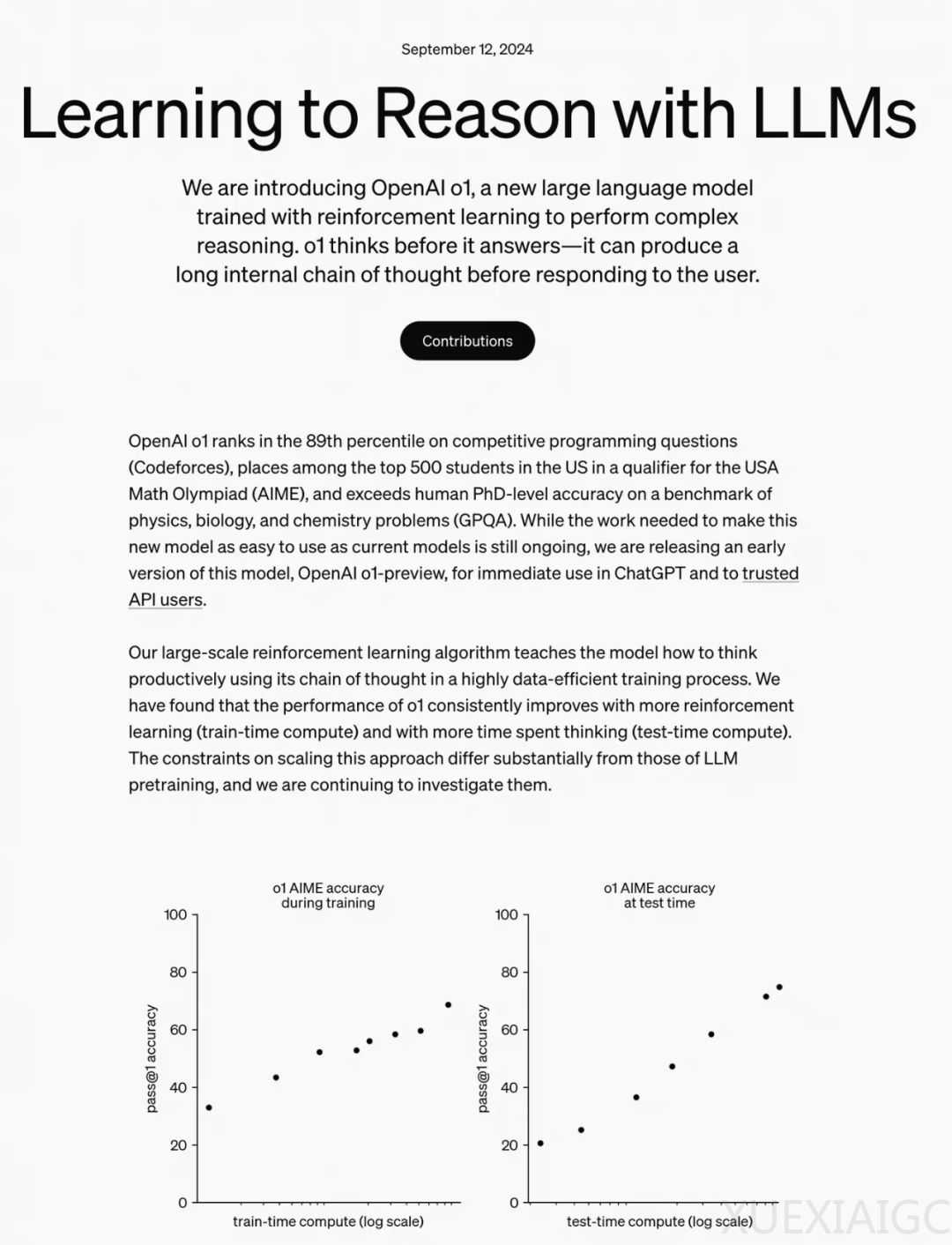
OpenAI最近推出的Self-Play RL新模型o1在数理推理领域取得了显著成绩,并提出了train-time compute和test-time compute两个新的RL Scaling Law。o1是一个多模态模型,其在多模态框架中取得了78.1分的高分,显示出其技术路线的创新性。o1的性能提升不仅依赖于训练时的强化学习,还需要在推理时进行思考,这表明预训练的scaling已经达到极限,主要收益需要在post-train阶段获得。
o1的推理能力通过一个解密例子得到了展示,模型能够逐步思考、提出假设并反思,最终得出正确答案。这种推理能力是通过inference time thinking实现的,即模型在回答问题前会进行长时间的思考。o1的这种思考流程是其与其他大模型的主要区别,它能够在没有人类参与的情况下完成假设提出、验证和反思。
Noam Brown,OpenAI reasoning方向的新生代力量,他的研究思路对o1的发展有着重要影响。大语言模型的学习策略在RLHF成功后出现了摇摆,但Self-Play的出现让人们期待模型能够通过自我博弈持续提升策略。Self-Play的成功需要Generator和Verifier都足够强,而目前Reward Model的准确度正在不断提升,使得Self-Play成为可能。
在技术路线上,o1可能采用了self-play actor-critic RL结合generator和verifier系统,或者self-play actor-critic RL结合generator和self verifier。这些技术路线都减少了人类监督的信号,更多地依赖于强化学习。o1的发布预示着大语言模型在各个领域通过Self-Play突破专有领域的可能性,尽管目前o1-preview版本可能还不是完全体,但其未来的潜力值得期待。
原文和模型
【原文链接】 阅读原文 [ 8667字 | 35分钟 ]
【原文作者】 AI大模型实验室
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★☆☆


相关文章


