三个月、零基础手搓一块TPU,能推理能训练,还是开源的
文章摘要
【关 键 词】 大模型、AI芯片、TPU构建、矩阵乘法、模型训练
大模型技术发展使 AI 专用芯片受关注,谷歌 TPU 是典型例子,其自 2015 年部署后已发展到第 7 代,推动了大模型技术进展。加拿大西安大略大学工程师 Surya Sure 等人利用暑假构建出开源的 ML 推理、训练芯片 TinyTPU。
他们造 TPU 的原因有:构建用于机器学习工作负载的芯片很酷;此前没有同时进行推理和训练的机器学习加速器完整开源代码库。他们以“始终尝试‘Hacky Way’”为设计理念,不依赖人工智能代写代码,尽可能学习深度学习等基础知识。
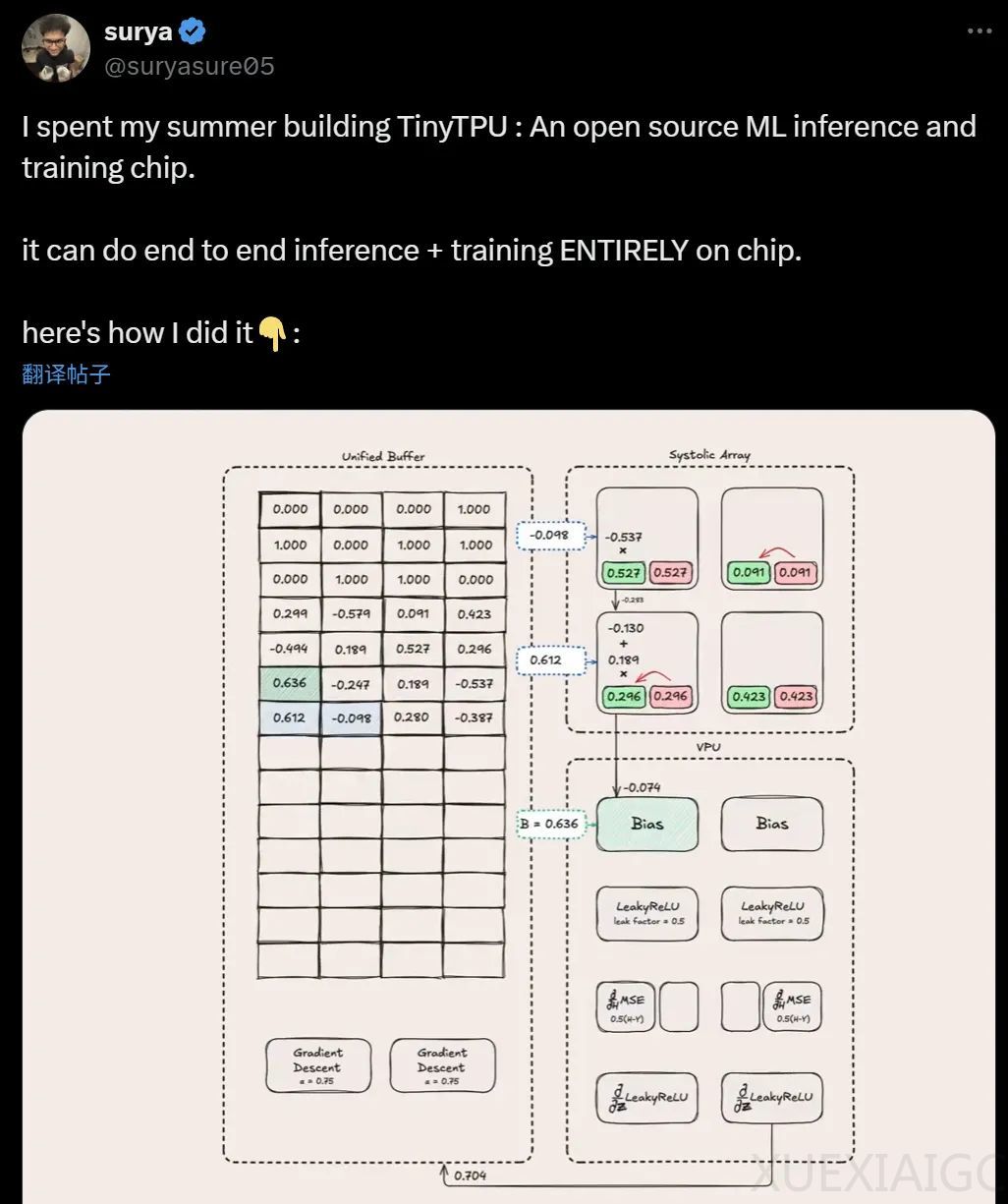
TPU 是谷歌设计的专用芯片,专用于执行数学运算,能高效完成机器学习模型的推理和训练。硬件设计中,时钟周期是处理时间单位,用 Verilog 语言描述硬件。TPU 执行矩阵乘法高效,其核心是脉动阵列,由处理单元组成,可脉动执行矩阵乘法。
构建 TPU 时,他们从理解神经网络基础开始,针对 XOR 问题进行推理和训练。为进行连续推理,需处理多维数据,他们简化维度,使用 2×2 脉动阵列。执行矩阵乘法用脉动阵列,还对输入和权重矩阵进行旋转、交错、转置等操作。
在硬件中执行矩阵乘法后,需添加偏差和应用激活函数,采用流水线技术提高效率,还传播“启动”信号。为解决更换权重问题,采用双倍缓冲机制,使脉动阵列能持续推理。最后创建控制单元和自定义指令集,实现推理功能。
训练方面,可将推理架构用于训练。训练时用损失函数衡量模型表现,通过链式法则逐层计算梯度并反向传播。发现反向传播与前向传播有美妙对称性,将相关模块统一为向量处理单元,提高可扩展性和灵活性。为存储前向传播数据创建统一缓冲区,对激活导数模块进行优化。最终通过前向传播、反向传播和权重更新训练网络,最初的矩阵乘法想法发展成完整训练系统。
原文和模型
【原文链接】 阅读原文 [ 7810字 | 32分钟 ]
【原文作者】 机器之心
【摘要模型】 doubao-1-5-pro-32k-250115
【摘要评分】 ★★★★★


相关文章


